

Определение интеллектуального содержания программ
Соотношения для объема и уровня программы, рассмотренные ранее, приводят к интересному выводу. Если произведение объема на уровень любого алгоритма действительно не изменяется при выражении его на различных языках, то это свойство можно считать фундаментальным. И хотя интуитивно ясно, что в машинном коде требуется большая степень детализации для того, чтобы «сказать то же», что и на языке Паскаль, пока еще отсутствует способ, позволяющий измерить, «сколько» же было сказано в каждом случае. Но если постулировать, что любые две эквивалентные программы в самом деле «говорят одно и то же», мы сможем ответить на вопрос «сколько?».
Меру того, сколько было сказано в программе, логичнее было бы назвать информационным содержанием программы, но теория информации Шеннона раньше других завладела смыслом этого термина, правда, для указания лишь объема сообщения без учета его уровня.
Поэтому «информационое содержание» программы мы заменим понятием интеллектуального содержания и определим как:
I = 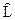 ´V (3.6)
´V (3.6)
С помощью уравнений (2.1) и (3.5) это выражение можно представить в виде

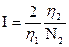 ´(N1 N2) log2(h1 h2) , (3.7)
´(N1 N2) log2(h1 h2) , (3.7)
где все члены в правой части доступны непосредственному измерению, исходя из любого выражения алгоритма. Интеллектуальное содержание, вычисленное с помощью уравнения (3.6), приближенно равно потенциальному объему V*, полученному из уравнения (3.4). Следовательно, поскольку V* не зависит от языка, на котором выражен алгоритм, интеллектуальное содержание также не должно от него зависеть .
Эту инвариантность можно продемонстрировать, оценив интеллектуальное содержание программ, реализующих алгоритм Евклида на разных языках. Выше мы рассмотрели метрики алгоритма Евклида, реализованного на Паскале и СИ (приведены в таблицах 2 и 3). Для этих программ значения интеллектуального содержания будут равны:
Паскаль: I = ´V = 0.0476 * 254.4 = 12.11;
СИ: I = ´V = 0.0606 * 224.8 = 13.62;
Теперь рассмотрим существенно отличный от этих двух вариант реализации алгоритма поиска наибольшего общего делителя (НОД), основанный на выборе значений НОД из заранее подготовленной таблицы значений. Пусть в качестве операнда «TABLE» в программу включен массив из 1000 строк и 1000 столбцов, содержащий заранее вычисленные значения НОД. Тогда алгоритм вычисления сводится к выбору значения НОД из двумерного массива по индексам, равным аргументам функции НОД и может быть представлен в виде:
TABLE: 0,1,…………………….
0,1,…………………….
…………………………
…………………………
GCD := TABLE [A,B]
Подсчет частот для алгоритма вычисления НОД в виде «просмотра таблицы» представлен в табл. 4.
Таблица 4
| J | Оператор | f1,j | J | Операнд | f2,j |
| , | 1 000 001 | TABLE | 1 000 001 | ||
| : | A | ||||
| := | B | ||||
| [ ] | CGD | ||||
| h1=4 | N1=1 000 004 | h2=4 | N2=1 000 004 |
Соответственно, значение интеллектуального содержания такой программы будет равно
´(N1 N2) log2(h1 h2) = 2/4 * 4/1000004 *2*1000004* log2(8) = 4*3 =12
В потенциальном языке, этот алгоритм будет записан в виде одного оператора
GCD(A, B, GCD) , для которого h1=N1=2; h2=N2=3.
И значение интеллектуального содержания программы на потенциальном языке будет
´(N1 N2) log2(h1 h2) = 2/2 * 3/3 *5* log2(5) = 11.6
В табл. 5 указаны данные для всех четырех версий алгоритма Евклида, а также вычисленное с помощью уравнения (3.7) интеллектуальное содержание I .
Таблица 5
| Язык | h1 | h2 | N1 | N | I |
| Паскаль | 12.11 | ||||
| СИ | 13.62 | ||||
| Потенциальный | 11.6 | ||||
| Просмотр таблицы | 1 000 004 | 2 000 0088 |
Как и следовало ожидать, с уменьшением уровня, используемого в реализации алгоритма, пропорционально возрастает требуемый объем, поэтому интеллектуальное содержание колеблется в пределах приблизительно ±10% от его среднего значения { 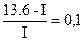 ;
; 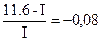 }.
}.
Поскольку данное свойство остается неизменным при изменении языка и лишь усиливается с увеличением сложности задачи, оно определяет не зависящую от языка меру содержания, внутренне присущего программе.
Пока параметры I и V* используются только как вспомогательные величины, они являются весьма полезными метрическими характеристиками, которые задают меру того, «сколько» было сказано, но ничего не говорят о важности сказанного. То есть программные параметры показывают, насколько хорошо написана программа, но не определяют, нужно ли было вообще ее писать.
§
Если мы ограничим понятие работы в программировании умственной деятельностью, затрачиваемой на превращение заранее разработанного алгоритма в реализацию на языке, которым исполнитель свободно владеет, то метрические характеристики и понятия, введенные выше, дадут нам возможность проникнуть в суть процесса программирования и образуют исходную систему для его количественной оценки. Простое соотношение между этими метрическими характеристиками и работой, выполняемой программистом, может быть получено с помощью шести шагов, описанных ниже в общих чертах.
Вывод уравнения работы
1. Как и ранее, допустим, что любая реализация какого-либо алгоритма заключается в N-кратном выборе из словаря, состоящего из h элементов.
2. Предположим далее, что каждый выбор из словаря h неслучаен. Исследования методов сортировки показали, что, за исключением хеширования, самым быстрым способом поиска в упорядоченном списке является двоичный поиск, при котором список многократно делится пополам до тех пор, пока не будет найден нужный элемент. Полученное в результате число сравнений равно двоичному логарифму числа элементов в списке. Следовательно, эффективный процесс, эквивалентный двоичному поиску , требует log2h сравнений для нахождения элемента.
3. На основании шагов 1 и 2 можно заключить, что программа порождается выполнением N ´ log2h мысленных сравнений.
4. Поскольку объем программы V определяется как
V = N log2h, (4.1)
из шага 3 следует, что он равен числу мысленных сравнений, затрачиваемых на порождение программы.
5. Каждое мысленное сравнение содержит ряд элементарных мысленных различений, число которых является мерой сложности задачи. Из предыдущих результатов вытекает, что именно уровень программы L является величиной, обратной ее сложности.
6. Так как объем V равен числу мысленных сравнений, а величина, обратная уровню программы, т.е. 1/L, есть среднее число элементарных мысленных различений, входящих в каждое мысленное сравнение, общее число элементарных мысленных различений Е, требуемых для порождения программы, должно задаваться выражением
Е = 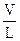 (4.2)
(4.2)
Можно выявить более глубокий смысл уравнения работы, если вспомнить уравнение (3.1)
L = 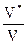
и подставить его в уравнение (4.2)
E = 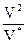 (4.3)
(4.3)
Уравнение (4.3) показывает, что мысленная работа по реализации любого алгоритма с данным потенциальным объемом в каждом языке пропорциональна квадрату объема программы. Как будет детально показано далее, из уравнения (4.3) следует, что, так как «квадрат суммы больше суммы двух квадратов», правильное разбиение на модули может уменьшить работу по программированию реализаций, разбитых на отдельные части. Теперь перейдем от подсчета элементарных мысленных различений к измерению времени.
§
Рассмотрим понятие, введенное психологом Джоном Страудом в работе «Тонкая структура психологического времени». Дж.Страуд определил «момент» как время, требуемое человеческому мозгу для выполнения наиболее элементарного различения. Он обнаружил, что в течение времени бодрствования человек воспринимает эти «моменты» со скоростью «от пяти до двадцати раз» в секунду. Следует отметить, что в диапазон приведенных Страудом цифр попадает и число кадровв секунду, превращающее кинофильм из последовательности отдельных снимков в непрерывное изображение. Обозначая через S число страудовских «моментов» в секунду, мы можем записать
5 £ S £ 20 в сек.
В дальнейшем S называется числом Страуда. Естественно, что любой человек, занимающийся реализацией алгоритма, может в зависимости от степени своей сосредото-ченности отвлечь какую-то часть мысленных различений на посторонние предметы. Пользуясь терминологией вычислительной техники, можно сказать, что, если он находится «в режиме разделения времени», S представляет собой лишь верхнюю границу. С другой стороны, если программист выполняет эквивалент машинной операции «запретить все прерывания» и сосредоточивает внимание на программировании, то применимо действительное значение S.
Для того чтобы перевести в единицы времени уравнение (4.2), имеющее размерность двоичных разрядов или различений, разделим обе его части на число различений в единицу времени. В результате получим
T^ = 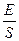 =
= 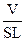 =
= 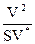 (4.4)
(4.4)
Символ ^ здесь указывает на то, что с помощью этого уравнения вычисляется приближенное, а не наблюдаемое время программирования.Уравнение (4.4) можно выразить через основные параметры, если подставить в него вместо V правую часть уравнения (2.1), а вместо L — правую часть уравнения (3.5)
T = 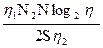 (4.5)
(4.5)
При этом, естественно, 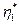 =2.
=2.
В предыдущем выводе подразумевалось, что все программы совершенны, т. е. не имеют несовершенств. Хотя это допущение более или менее обосновано для опубли-кованных программ, оно необязательно. Поэтому откажемся от него по крайней мере в первом приближении, подставив 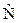 вместо N в уравнение (4.5). Если при этом задается уравнением длины, приходим к выражению
вместо N в уравнение (4.5). Если при этом задается уравнением длины, приходим к выражению
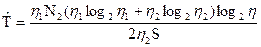 , (4.6)
, (4.6)
где, за исключением числа Страуда S, все параметры в правой части доступны непосред-ственному измерению для любой реализации алгоритма.
Уровень языка.
Материал, изложенный в лекции 3, выявил полезное соотношение между уровнем программы L и ее объемом V. Для любого алгоритма, который переводится с одного языка на другой, с увеличением объема уровень уменьшается в той же пропорции. В результате произведение L на V равняется потенциальному объему V* данного алгоритма. С другой стороны, если язык реализации остается одним и тем же, а разрешено менять сам алгоритм, имеется другое, но похожее соотношение. В этом случае с увеличением потенциального объема V* уровень программы L уменьшится в том же отношении. Следовательно, произведение L на V* остается неизменным для любого языка. Это произведение, называемое уровнем языка, обозначается через l и записывается в виде:
l = L´V* (4.7)
§
Значительная часть усилий и времени, затрачиваем на реализацию большинства программ для ЭВМ, приходится на их отладку, т. е. выявление и устранение ошибок типа “лишних и недостающих элементов”, внесенных в начальный период написания программы. Следовательно, любое обоснованное представление о числе первоначальных ошибок, ожидаемых в данной программе, даст важную оценку для практики. Предлагаемая метрика предсказывает число первоначальных ошибок (до отладки и тестирования) и не может служить доказательством правильности (корректности) программы, даже если ее значение равно нулю.
Время, требуемое на разработку программы, характеризуется числом элементарных мысленных различений Е. Следовательно, число моментов, в которые можно сделать ошибочное различение, также определяется значением Е или связанным с ним значением объема программы V. По утверждениям психолога Джорджа Миллера (закон “7±2”) мозг человека может в своей “сверхбыстрой” памяти обрабатывать пять “объектов” одновременно (т. е. получать из них результат). Представив эту способность мозга как Екрит, получим ее программное значение.
Пусть каждый объект так же, как и результат, соответствует единице уникальных операндов в потенциальном языке, т. е. h2* = 6. С помощью равенств h1* = 2 и
V* = (h1* h2*) log2 (h1* h2*) (4.11)
получаем
V*крит = (2 6)log2(2 6) = 24 (4.12)
Далее из уравнения (4.8) имеем
E = (V*)3/l2 ,
а из табл. 6 получаем для английского языка l= 2,16. Тогда для описания программы на уровне английского языка приходим к следующему выводу
Екрит = (24)3 * (2,16)2 = 3000 (4.13)
Определим теперь Ео как среднее число элементарных различений между возможными ошибками в программировании, а В — как число переданных ошибок в программе. Можно ожидать, что
В = Е/Ео, (4.14)
но при этом не будет учтено какая-либо избыточность в создаваемой программе.
Однако уровень программы L, собственно, и является мерой такой избыточности. Заметим, что только в потенциальном языке, на котором любая программа может быть выражена в виде вызова процедуры, не повторяются ни операторы, ни операнды. Для такого потенциального языка L = 1. Для всех же остальных языков L уменьшается с увеличением избыточности.
Следовательно, вместо уравнения (4.14) реальнее ожидать, что
B = L * Е/Ео. (4.15)
По правилам алгебры произведение L ´ Е можно заменить на V, что даст:
B=V/Eo. (4.16)
Если теперь приравнять Eo из уравнений (4.14) значению Екрит, найденному по уравнению (4.13), то получим соотношение
B= V / 3000 (4.17)
C другой стороны, подставив в (4.17) выражение для V из (4.10), получим
B= (V*)2 / (3000*l) (4.18)
Из выражения (4.18) следует, что поскольку для определения потенциального объема необходимо только знание числа независимых входных и выходных параметров программы, задаваемого в техническом задании на ее разработку, то после выбора языка программирования потенциальное количество ошибок можно оценить до написания программы.
§
Структурная сложность программ определяется:
· числом взаимодействующих компонент;
· числом связей между компонентами;
· сложностью взаимодействия компонент.
При функционировании программы разнообразие ее поведения и разнообразие связей между ее входными и результирующими данными в значительной степени определяется набором маршрутов(чередующихся последовательностей вершин и дуг графа управления), по которым исполняется программа.
Установлено, что сложность программного модуля связана не столько с размером (числом команд) программы, сколько с числом маршрутов ее исполнения и их сложностью.
Для повышения качества программымаршруты возможной обработки данных должны быть тщательно проверены при создании программы и тем самым определяют сложность ее разработки. Данную метрику сложности можно использовать для оценки трудоемкости тестирования и сопровождения модуля, а также для оценки потенциальной надежности его функционирования. Проведенные исследования подтверждают достаточно высокую адекватность использования структурной сложности программ для оценки трудоемкости тестирования, вероятности ненайденных ошибок и затрат на разработку программных модулей в целом.
Все маршруты исполнения программного модуля условно можноразделить на две группы:
· вычислительные маршруты;
· маршруты принятия логических решений.
Первая группа маршрутов включает в себя маршруты арифметической обработки данных и предназначена для преобразования величин, являющихся квантованными результатами измерения непрерывных физических характеристик (квазинепрерывных переменных).
Для проверки вычислительных маршрутов можно построить достаточно простую стратегию их проверки. Во всем диапазоне входных переменных нужно выбрать несколько характерных точек (предельные значения, значения в точках разрыва и несколько (1-3) промежуточных значений), для которых проверяется работоспособность программы. Предполагается, что в большинстве промежуточных точек программу можно не проверять из-за гладкости значений непрерывных переменных.
Сложность вычислительных маршрутов оценивается следующей формулой:
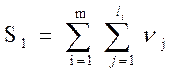 ,
,
где m – количество маршрутов исполнения программы;
li – число данных обрабатываемых в i-ом маршруте;
nj – число значений обрабатываемых данных j-го типа (2 £ nj £ 5)
Расчет сложности программы по данной формуле имеет значительную неопределенность из-за произвола в выборе количества значений nj при изменении входных данных. Поскольку доля вычислительной части во многих сложных программных комплексах обработки информации относительно невелика (общее число арифметических операций не выходит за предел 5–10%), вычислительные маршруты не определяют структурную сложность программ.
Сложность маршрутов принятия логических решенийоценивается формулой:
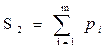 ,
,
где pi – число ветвлений или число проверяемых условий в i-ом маршруте.
Общая сложность программы определяется формулой:
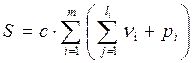 ,
,
где с– некоторый коэффициент пропорциональности, определение которого является сложной задачей.
Выделение маршрутов исполнения программы, минимально необходимых для ее проверки, и оценки структурной сложности могут осуществляться по различным критериям. Наилучшим, по-видимому,является критерий, позволяющий выделить все реальные маршруты исполнения программы при любых сочетаниях исходных данных. При этом формирование маршрутов зависит не только от структуры программы, но и от значений переменных в различные моменты времени. Такое выделение маршрутов трудно формализовать, и оно представляется очень трудоемким для оценки показателей сложности структуры.
§
Критерий 1. По этому критерию граф программы по управлению должен быть покрытминимальным набором путей, проходящих через каждый оператор ветвления по каждой дуге. Повторная проверка дугне оценивается и считается избыточной. При этом в процессе проверки гарантируется выполнение всех передач управления между операторами программы и каждого оператора не менее одного раза.
 Поток управления– последовательность выполнения различных модулей и операторов программы.
Поток управления– последовательность выполнения различных модулей и операторов программы.
Граф потока управления– ориентированный граф, моделирующий поток управления программы.
В настоящее время разработаны алгоритмы, позволяющие автоматизировать процесс получения минимального множества маршрутов по этому критерию.
Рассмотрим структурную сложность типичной программы управления, содержащей 100 – 200 команд, граф потока управления которой, представленный на рис.3, содержит 14 вершин, 20 дуг и 3 цикла.
Для полной проверки этой программы по первому критерию достаточно следующих четырех маршрутов:
M1: 1 – 2 – 14
M2: 1 – 3 – 4 – 6 – 8 – 6 – 8 – 14
M3: 1 – 3 – 5 – 7 – 9 – 10 – 11 – 12 – 13 – 14
M4: 1 – 3 – 4 – 5 – 7 – 9 – 10 – 9 – 10 – 11 – 7 – 9 – 10 – 11 – 12 – 14
Рис.3
Структурная сложность программы по первому критерию вычисляется следующим образом:
m
S = S pi ,
i =1
гдеpi –количество вершин ветвления в i—том маршруте без учета последней вершины
m1: 1 — 2 — 14 = 1
m2: 1 — 3 — 4 — 6 —8 — 6 — 8— 14 = 5
m3: 1 — 3 — 5 — 7 — 9 — 10 — 11 — 12 — 13 — 14 = 5
m4: 1 — 3 — 4 — 5 — 7 -9— 10 — 9 — 10 — 11 — 7 — 9 — 10 — 11 — 12 — 14 = 9
Таким образом, сложность программы, представленной графом на рис.3, составляет некоторую метрику в 20 единиц.
Недостаток первого критерия: не учитывается комбинаторика сочетания условий на разных участках маршрутов (например, при сочетаниях ветвлений в вершинах 3 и 12).
Критерий 2. Основан на анализе базовых маршрутов в программе, формируемых и оцениваемых на основе цикломатического числа графа потока управления программы (см. работы Т.МcCabe и В.В.Липаева).
Цикломатическое число Z исходного графа программы определяется формулой
Z = Y — N 2*W,
где Y – общее число дуг в графе;
N – общее число вершин в графе;
W – число связных компонент графа.
Число связных компонент графа Wравно количеству дуг, необходимых для превращения исходного графа в максимально связный граф.
Максимально связным графом называется граф, у которого любая вершина доступна из любой другой вершины.
Максимально связный граф получается из исходного графа путем замыкания конечных и начальной вершин. Для большинства корректных (не содержащих висячих и тупиковых вершин) графов достаточно одной замыкающей дуги.
Для рассматриваемого графа максимально связанный граф получается путем добавления дуги (14, 1)
Z = Y — N 2´P = 20 — 14 2´1 = 8
Второй критерий (выбранный по цикломатическому числу) требует однократной проверки или тестирования каждого линейно-независимого цикла и каждого линейно-независимого ациклического участка программы.Каждый линейно-независимый ациклический маршрут или циклотличается от всех остальных хотя бы одной вершиной или дугой, т.е. его структура не можетбыть полностью образована компонентами других маршрутов.
 При использовании второго критерия количество проверяемых маршрутовравно цикломатическому числу.
При использовании второго критерия количество проверяемых маршрутовравно цикломатическому числу.
M1: 6 – 8
m2: 9 – 10Линейно-независимые циклические маршруты
m3: 7 – 9 – 10 – 11
 m4: 1 – 2 – 14Линейно-
m4: 1 – 2 – 14Линейно-
§
m6: 1 – 3 – 5 – 7 – 9 – 10 – 11 – 12 – 14ациклические
m7: 1 – 3 – 4 – 5 – 7 – 9 – 10 – 11 – 12 – 13 – 14маршруты
M8: 1 – 3 – 4 – 5 – 7 – 9 – 10 – 11 – 12 – 14
Определение структурной сложности по второму критерию:
m1: 6 — 8= 1
m2: 9 — 10= 1
m3: 7 — 9 — 10 – 11 = 2
m4: 1 — 2 – 14 = 1
m5: 1— 3 — 4 — 6 — 8 – 14 = 4
m6: 1 — 3 — 5 — 7 — 9 — 10 — 11 — 12 – 14 = 5
m7: 1 — 3 — 4 — 5 — 7 — 9 — 10 — 11 — 12 – 14 = 6
m8: 1 — 3 — 4 — 5 — 7 — 9 — 10 — 11 — 12 — 13 – 14 = 6
Для правильно структурированных программ (программ, которые не имеют циклов с несколькими выходами, не имеют переходов внутрь циклов или условных операторов и не имеют принудительных выходов из внутренней части циклов или условных операторов) цикломатическое число Zможно определитьпутем подсчета числа вершинnв, в которых происходит ветвление. Тогда
Z = nв 1
Для рассматриваемого примера Z = 7 1 = 8(ветвления имеют место ввершинах графа 1, 3, 4, 8, 10, 11, 12).
Исследования графов реальных программных модулей с достаточно большим фиксированным числом вершин показали, что:
· Суммарная сложность тестов почти не зависит от детальной структуры графа и в основном определяется числом предикатов – ветвлений графа;
· При неизменном числе вершинв широких графах имеется большее количество маршрутов, чем в узких графах, но маршруты в среднем короткие. В узких графахчисло маршрутов сокращается по сравнению с широкими, но маршруты становятся длиннее. В результате величина S2при изменении структуры графов изменяется меньше, чем цикломатическое число и сильнее коррелирована с числом вершин.
В.В. Липаев показал, что для Z £ 10 модули корректно проверяемы и число ошибок в таких модулях будет минимальным. Приемлемыми значениями Z считаются 10 £ Z £30. При Z > 30устранить ошибки в процессе тестирования практически невозможно.
Для автоматического анализа графов по второму критерию с помощью ЭВМ используются матрицы смежности и достижимости графов.
Матрица смежности – это квадратная матрица, в которой 1 располагается в позиции (i, j),если в графе имеется дуга (i, j).
Для рассматриваемого графа программы матрица смежности имеет вид, показанный в табл.7.
Таблица 7
Матрицей достижимости называется квадратная матрица, в которой 1 располага-ется в позиции, соответствующей дуге (i, j). Для рассматриваемого графа программы матри-ца достижимости имеет вид, показанный в табл.8.
Таблица 8
Матрица достижимости является основнойдля вычисления маршрутов по второму критерию. Используя ЭВМ, матрицу достижимости можно получить из матрицы смежности путем возведения ее в степень, величина которой равна числу вершин без последней в исходном графе.
С помощью матрицы достижимости можно сравнительно просто выделить циклы, отмечая диагональные элементы, равные 1, и идентичныестрок.
Для рассматриваемого примера одинаковыми являются строки 6и 8, которые имеют 1на диагонали, следовательно, вершины 6и 8образуют цикл. Аналогично можно выделить еще два маршрута с циклами, образованными вершинами 9и10 и 7, 9, 10и11 соответственно.
Более сильные критерии проверки и определения сложности структуры программы включают требования однократной проверки не только линейно-независимых, но и всех линейно-зависимых циклов и ациклических маршрутов.
Критерий 3. Этот критерий основан на выделении полного состава базовых структур графа программы и заключается в анализе хотя бы один раз каждого из реальных ациклических маршрутов исходного графа программы и каждого цикла, достижимого из всех этих маршрутов.
Если из некоторого ациклического маршрута исходного графа достижимы несколько элементарных циклов, то при тестировании должны исполняться все достижимые циклы.
Для рассматриваемого примера по данному критерию необходимо исполнить 6 ациклических маршрутов и 5 маршрутов, из которых достижимы элементарные циклы.
M1: 1 – 2 – 14
m2: 1– 3– 4– 6 – 8 – 14
M3: 1 – 3 – 5 – 7 – 9 – 10 – 11 – 12 – 14
M4: 1 – 3 – 4 – 5 – 7 – 9 – 10 – 11 – 12 – 14
M5: 1 – 3 – 5 – 7 – 9 – 10 – 11 – 12 – 13 – 14
m6: 1 – 3– 4 – 5 – 7 – 9 – 10 – 11 – 12 – 13 – 14
m7: 1 – 3– 4– 6 – 8– 6 – 8 – 14
m8: 1 – 3 – 5 – 7 – 9 – 10 – 9 – 10 – 11 – 7 – 9 – 10 – 11 – 12 – 14
m9: 1 – 3 – 4 – 5 – 7 – 9 – 10 – 9 – 10 – 11 – 7 – 9 – 10 – 11 – 12 – 14
m10: 1 – 3 – 5 – 7 – 9 – 10 – 9 – 10 – 11 – 7 – 9 – 10 – 11 – 12 – 13 – 14
m11: 1 – 3 – 4– 5 – 7 – 9 – 10 – 9 – 10 – 11 – 7 – 9 – 10 – 11 – 12 – 13 – 14
Определим структурную сложность заданной программы по третьему критерию:
m1: 1 — 2 — 14 = 1
m2:1—3—4 – 6 –8– 14 = 4
m3: 1 — 3 —5 — 7 — 9 — 10 — 11 — 12 — 14 = 5
m4: 1 — 3 — 4 — 5 — 7 — 9 — 10 — 11 — 12 – 14 = 6
m5: 1 — 3 — 5 — 7 — 9 — 10 — 11 — 12 — 13 — 14= 5
m6: 1 — 3 — 4 — 5 — 7 — 9 — 10 — 11 — 12 — 13 – 14 = 6
m7: 1—3—4— 6 —8— 6 —8— 14 = 5
m8: 1 — 3 — 5 — 7 — 9 — 10 — 9 — 10 — 11 — 7 — 9 — 10 — 11 — 12 – 14 = 8
m9: 1— 3— 4— 5 — 7 — 9 — 10 — 9 — 10 — 11 — 7 — 9 — 10 — 11 — 12 – 14 = 9
m10: 1— 3— 5 — 7 — 9 — 10 — 9 — 10 — 11 — 7 — 9 — 10 — 11 — 12 – 13 – 14 = 8
m11: 1— 3 — 4 — 5 — 7 — 9 — 10 — 9 — 10 — 11 — 7 — 9 — 10 — 11 — 12 – 13 – 14 = 9
S2 = 1 4 5 6 5 6 5 8 9 8 9 = 66
Особенностью четырех последних маршрутов с циклами, так же как соответствующих им ациклических маршрутов, является полный переборсочетаний ветвлений в вершинах 3 и 12.
Приведенные критерии для оценки сложности программных модулей характеризуют в каждом случае минимально необходимые величины проверок по каждому критерию. Для проверки реальных программ это количество проверок может быть недостаточно (например, циклы желательно проверять на одном-двух промежуточных значениях, а также на максимальном и минимальном количествах исполнения циклов). Оценить достаточность проверок программы значительно труднее, так как при этом, кроме сложности структуры, необходимо анализировать сложность преобразования каждой переменной во всем диапазоне ее изменения и при сочетаниях с другими переменными.
§
Наряду с аналитическими методами для исследования и оценки параметров программ активно используются измерительные методы. Привлекательной стороной этих методов является их высокая достоверность. Поэтому они применяются для проверки имитационных и аналитических методов оценки характеристик программ по принципу: практика – лучший критерий истины.
В целом измерительные методы имеют следующее назначение:
1) Измерение параметров потребления программами ресурсов вычислительной системы с целью устранения дефектов производительности.
2) Предварительное измерение параметров системы для имитационных или аналитических моделей программ перед их последующим использованием. Это связано со сложностью оценки параметров моделей, особенно при использовании новых системных средств с неизвестными динамическими параметрами (например устройств ввода-вывода, нового процессора с не вполне известными характеристиками и т.п.).
3) Проверка адекватности имитационных или аналитических моделей и методов расчета характеристик выполнения программ по результатам моделирования.
Необходимые условия применения измерительных методов:
1) Наличие готовой программы, подлежащей измерительному исследованию;
2) Наличие реальной вычислительной системы (а не её модели) для прогона программы;
3) Наличие аппаратных или программных средств проведения измерений;
4) Создание условий снижения искажений, вносимых в функционирование системы в процессе проведения измерений, до приемлемого уровня.
Общая схема проведения измерений показана на рис.4.
Рис.4
Представленная на рис.4 схема измерений включает следующие компоненты:
1) Исследуемую ВС с установленными программами.
2) Средства регистрации параметров потребляемых ресурсов при выполнении данной рабочей нагрузки.
3) Архив для хранения результатов многочисленных измерений.
4) Результаты измерений обрабатываются некоторой ВС (отдельная ВС или та же, на которой снимались измерения, но после выполнения сеанса измерений.).
5) Рабочая нагрузка — одна или несколько программ или наборов данных для получения статистики проводимых измерений.
Процесс измерения подготовки и проведения измерений включает следующие три этапа:
1) Выбор рабочей нагрузки представительной с точки зрения исследования параметров выполнения программы на исследуемой системе.
2) Выбор (разработка) средств регистрации параметров потребления ресурсов системы.
3) Выбор (разработка) алгоритмов расчетов характеристик программ по результатам измерений.
Все эти три этапа увязываются в единое целое в зависимости от того, какой проводится эксперимент и как он планируется.
Существует два основных способа регистрации измеряемых параметров:
— трассирующий:
— выборочный.
При трассирующем способе измеряемые параметры фиксируются в момент наступления какого-либо события, связанного с изменением управляющих таблиц операционной системы. В результате получаем множество значений ri потребления i — го ресурса, взятых в моменты времени наступления j-го события.
{ri (ej)} e -event.
В качестве событий обычно рассматриваются обращения к некоторым операторам программы, программным модулям, наборам данных или устройствам системы.
Если рассматривается емкостная нагрузка — то берутся наборы данных, а если временная нагрузка — то выбираются обращения к программным компонентам.
Вторая группа событий — прерывания процессора как внутренние, так и внешние, наступаю-щие при обмене данными с внешними устройствами.
При выборочном способе измерения производятся в моменты времени tj, обычно равноудаленные друг от друга.
tj = tj-1 Dt
Трассирующий метод характеризуется меньшим количеством измерений параметров и сильной зависимостью от конкретной рабочей нагрузки.
Выборочный метод имеет на 1-2 порядка большее число измерений параметров в связи со статистическими методами последующей обработки результатов измерений.
Выборочный способ применяется потому, что регистрация событий — дело довольно сложное, но для того, чтобы не пропустить момент наступления события, измерения надо производить часто (через малые промежутки времени) и, как следствие, приходится брать много лишних отсчетов измеряемой величины, поэтому количество измерений возрастает.
Достоинства выборочного способа — более простой, т.к. не надо регистрировать наступление событий.
Средства обеспечивающие регистрацию измерений параметров называются измерительными мониторами.
К измерительным мониторам предъявляются следующие требования:
1) Минимальные искажения в системе при выполнении программы.
Искажения бывают двух типов:
— временные искажения — искажения связанные с рассогласованием реального времени наступления события и временем регистрации параметра монитором;
— пространственные искажения — сам монитор и собираемые им данные занимают место в памяти ЭВМ и препятствуют размещению объектов программы).
2) Достаточная точность измерений.
3) Достаточно высокая разрешающая способность (по интервалам времени фиксации событий).
4) Независимость от измеряемой системы (программы).
5) Низкая стоимость (Чтобы не отпугивать пользователей.)
6) Простота использования.
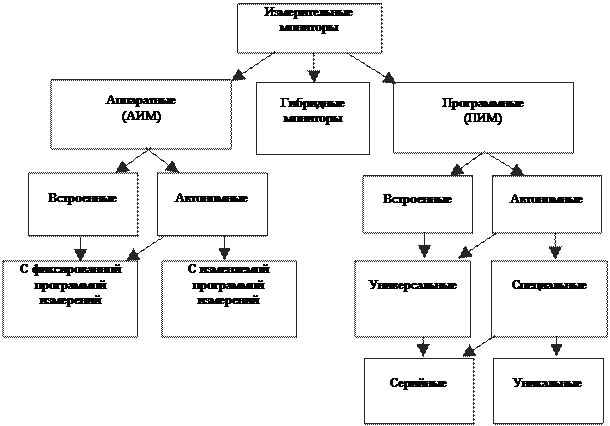 Классификация измерительных мониторов.
Классификация измерительных мониторов.
Общую схему классификации измерительных мониторов можно представить в виде, пока-занном на рис.5.
Рис.5
Обычно с помощью измерительных мониторов получают следующие типы характеристик:
1. Трассировочная запись — множество пар {ri ; tj } значений, где:
ri — некоторое i-ый параметр потребления ресурсов системы;
tj — интервал времени между предыдущим и текущим регистрируемым событием, либо момент регистрации.
Трассировочная запись является наиболее полной характеристикой поведения анализируемой программы и может содержать 10-ки тысяч записей. Её достоинством также является хронология последовательности выполнения программы.
2. Профиль (динамический) выполнения программы.
Они делятся на две группы:
— частотные;
— временные.
Частотные профили определяют количественное распределение потребления рассматриваемых ресурсных параметров.
Временные профили задают распределение времён потребления ресурсов в абсолютном или относительных масштабах.
Достоинства профилей — позволяют выявлять узкие места выполнения программ в монопольном режиме. В дальнейшем можно улучшить эти участки программы изменением алгоритма или заменой программных действий аппаратными.
Недостаток профиля — не содержит хронологии потребления ресурсов программой и поэтому не позволяет проводить анализ для конвейерных систем и взаимодействующих процессов.
Общий недостаток трассировочных записей и снятия профилей — зависимость от рабочей нагрузки. Профиль более универсален, т.к. трассировочные записи вообще не содержат статистики.
Примеры частотного и временного профилей распределения арифметических команд некоторого процессора приведены в табл.9
Таблица 9
| Выполняемые операции. | Частотный профиль | Временной профиль | ||
| абсолютный | Относител. | |||
| Сложение с фикс.запятой | 514 раз | 0,5 мс | 4,46 % | |
| Умножение с фикс.запятой | 72 раз | 1,4 мс | 12,50 % | |
| Вычитание, сравнение | 256 раз | 0,3 мс | 2,68 % | |
| Деление | 14 раз | 2,0 мс | 17,86 % | |
| Операции с плав. Запятой | 78 раз | 7,0 мс | 62,50 % | |
3. Смеси (динамические) (команд/программ).
Позволяют оценивать для различных совокупностей команд или программ частотные распределения использования ресурсов системы. Для различных программ можно составлять различные смеси (смеси вычислительных задач, смеси для диалоговых сценариев, смеси для графических систем и т.п.). Смеси имеют меньшую зависимость от конкретных программ и предметную ориентированность. Позволяют анализировать производительность ВС в целом.
4. Коэффициенты загрузки позволяют оценить загруженность некоторого ресурса при выполнении программы как отношение времени использования ресурса к общему времени исполнения программы Кз = Тисп/Тобщ.
Аппаратные измерительные мониторы (АИМ).
АИМ подразделяются на встроенные и автономные.
Встроенные АИМ — включаются в аппаратуру системы заводом изготовителем, как правило, для выполнения тестовых измерений в фиксированном наборе внутренних точек устройств системы.
Основное назначение встроенного АИМ — для проверки, контроля и настройки ВС. Но т.к. в его составе могут находиться триггеры состояний схемы, счетчики и некоторые другие устройства, то они могут использоваться и ддя измерения параметров программ.
Автономные АИМ подключаются к измерительным точкам извне системы через специальные разъемы и могут задавать любые точки доступные для измерений. Автономные АИМ наиболее общий случай.
Рассмотрим структурную схему автономного АИМ, показанную на рис.6.
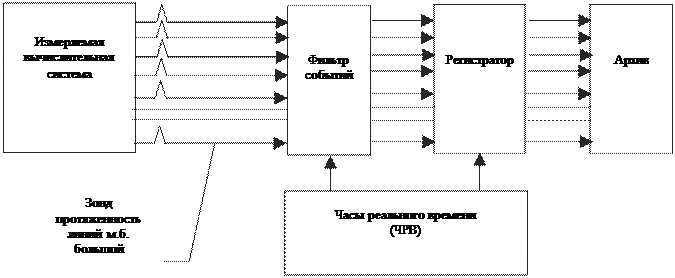
Рис.6
Зонд — высокоомный датчик сигналов, не влияющий на функционирование системы.
Фильтр событий – устройство, вырабатывающее сигнал истинности, при наступлении какого-либо события. Может содержать аналоговые компараторы для сравнения уровней сигналов с заданными границами, цифровые компараторы для сравнения кодов, простейшие автоматы типа детекторов последовательностей команд или адресов памяти (2-3 команды или адреса, повторяющиеся друг за другом могут служить признаком наступления события).
Регистратор — набор счетчиков, осуществляющих фиксацию и первичное сжатие результатов измерений.
Архив — место длительного хранения результатов измерений. Так как счетчики регистратора могут переполниться и потерять результаты измерений, то их содержание периодически переписываются в архив, откуда данные могут быть извлечены при необходимости.
Часы реального времени — служат для регистрации моментов наступления событий или длительностей интервалов времени между событиями.
Пример АИМ с фиксированной программой и последовательным входом (рис.7) для измерения коэффициента загрузки процессора или другого ресурса по формуле
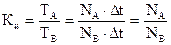
Рис. 7
Пример АИМ с фиксированной программой и параллельным входом для снятия частотного профиля операций процессора, используемых при выполнении программы.
Каждому коду операции процессора ставится в соответствие ячейка таблицы, размещаемой в памяти прямого доступа (ППД), подключаемой в инкрементном режиме. За одно обращение к ячейке ППД с заданным алресом читается ее содержимое, инкрементируется и возвращается в ту же ячейку. Смещение адреса ячейки задается выходом фильтра событий, фиксирующего операцию исполняемой команды программы. В результате ячейки таблицы работают как счетчики количества использования каждой операции процессора и формируют частотный профиль программы.

АИМ неудобны тем, что легко регистрируют события в аппаратных средствах, но менее ориентированы на измерения параметров, характеризующих выполнение программ. Более гибкими являются измерительные средства, в которых программно фиксируются события, а аппаратным способом осуществляется регистрация параметров при их наступ-лении — такой принцип работы заложен в гибридных измерительных мониторах (ГИМ).
Пример ГИМ для оценки распределения частот использования нерезидентных и резидентных модулей программы (например, при настройке конфигурации ОС) показан на рис.8. При ограниченном ресурсе основной памяти часть модулей резидентно располагается в памяти с произвольным доступом RAM, другие же модули загружаются в память по мере необходимости из дисковой памяти и после их использования память очищается. Так как нерезидентные модули загружаются в свободные сегменты памяти, их размещение может быть произвольным и поэтому на основе фиксации участков памяти, используемых ЭВМ в данный момент, трудно определить, какой модуль занимает процессорное время в данный момент (за исключением резидентных модулей).
 Место загрузки нерезидентного модуля в RAM можно выяснить из управляющих таблиц ОС измеряемой ЭВМ — но для этого надо использовать дополнительную измери-тельную ЭВМ, которая может программно получить доступ к управляющим таблицам ОС измеряемой ЭВМ и соответствующим образом настроить компараторы фильтра событий.
Место загрузки нерезидентного модуля в RAM можно выяснить из управляющих таблиц ОС измеряемой ЭВМ — но для этого надо использовать дополнительную измери-тельную ЭВМ, которая может программно получить доступ к управляющим таблицам ОС измеряемой ЭВМ и соответствующим образом настроить компараторы фильтра событий.
Рис.8
На рис.8 показаны:
— RAM — память с произвольным доступом; управляющие таблицы ОС хранят адреса загрузки и размеры модулей программы в RAM;
— Контроллер диска с триггером состояния «занято» позволяет фиксировать моменты выполнения операций чтения — записи информации на диск, изменяющих размещение нерезидентных модулей;
— Фильтр событий (включающий счетчики и компараторы с уставками адресов размещения модулей), управляемый измерительной ЭВМ, позволяет отслеживать, с какими модулями работает программа и как часто к ним идет обращение;
— Через ШВВ (шину ввода — вывода) измерительная ЭВМ связана с управляющими таблицами RAM измеряемой ЭВМ, что позволяет ей определять, какой модуль программы размещен в заданных адресах ОЗУ.
Гибридные измерительные мониторы сочетают достоинства аппаратных и программных мониторов, но являются более специализированными, чем программные, и дорогими.
§
Программные измерительные мониторы (ПИМ) — это совокупность команд или программ, выполняемых исключительно с целью проведения измерений. Обычно ПИМ – это специальные программные средства, под управлением которых производится выполнение программы на той же ЭВМ, на которой измеряемая программа и должна выполняться. При этом ПИМ собирает данные о ходе выполнения программ и накапливает их в памяти.
То, что эти команды ПИМ должна выполнять сама измеряемая система, приводит к возникновению искажений. Количество искажений зависит от частоты обнаруживаемых событий и от операций, выполняемых измерителем при обнаружении каждого события.
Идея использовать измерительные средства в процессе разработки программ — не нова. В настоящее время существует несколько типов таких программных средств. Особое место среди них занимают профилировщики. Профилировщики (называемые также анализаторами процесса выполнения программ) — это программы, позволяющие получить ряд количественных данных о процессе выполнения объекта разработки (снять профиль разрабатываемой программы) и на основании этих данных выявить в программе «узкие места», отрицательно сказывающиеся на эффективности ее работы. Профиль программы может содержать, например, следующую информацию о процессе выполнения программы:
— как и на что расходуется время работы программы;
— сколько раз выполняется данная строка программы;
— сколько раз и какими модулями вызывается данный модуль программы.
Один из самых известных профилировщиков — Turbo Profiler фирмы Borland International. Система Turbo Profiler контролирует каждый шаг выполнения программы и предоставляет подробные статистические сведения о всех этапах ее работы. Такой подход к измерениям позволяет проводить профилирование в интерактивном режиме и получать большое количество сведений о работе программы, но вносит большие временные искажения в процесс ее выполнения. Кроме того, для проведения измерительного эксперимента тестируемая программа должна быть откомпилирована с отладочной информации при отключении оптимизации компилятора. Это делает профилирование неадекватным реальному выполнению программы. Для получения достоверной информации о времени выполнения от программиста требуется достаточно высокая квалификация в методике планирования и проведения измерительного эксперимента. Таким образом, Turbo Profiler ориентирован прежде всего на профессиональных программистов. За счет грамотного планирования эксперимента и отказа от ряда сервисных функций можно повысить точность временных измерений до 55 мс. Тем не менее, такая точность в ряде случаев недостаточна.
Другой подход реализован, например, в пакете Interval Performance Monitoring (IPM) Калифорнийского Университета. IPM ориентирован исключительно на временные измерения и состоит из набора отдельных функций для замера времени и протоколирования результатов измерения. Функции вставляются в нужные места программы, после чего программа компилируется. Такой подход позволяет резко повысить точность измерений, но требует значительных дополнительных усилий по сбору и классификации полученной информации. Трудоемкость проведения измерительного эксперимента не позволяет считать системы типа IPM полноценными профилировщиками.
Многие из полезных принципов организации системы Turbo Profiler и пакета IPM были реализованы на кафедре МОЭВМ в ПИМ Sampler. Особенностью работы ПИМ Sampler являются:
1. Исследуемая программа запускается под управлением монитора и монитор берет на себя все функции по накоплению результатов измерений и протоколированию.
2. Исследуемая программа выполняется «естественным» образом, а не по шагам и без использования отладочной информации.
3. Измерения времени выполняются с максимально возможной точностью.
4. Искажения, вносимые ПИМ за счет потребления им ресурсов ЭВМ, минимальны и не сказываются на итоговых результатах.
5. По результатам измерений формируется файл отчета печатного вида и представление их в графической форме.
На этапе планирования измерительного эксперимента производится задание контрольных точек. После этого исследуемая программа компилируется. Задание контрольной точки предполагает вызов некоторой функции на языке программирования исследуемой программы. Назовем эту функцию функцией задания контрольных точек или просто функцией контрольных точек. Эта функция не должна вносить больших искажений в работу исследуемой программы. Для этого она должна быть небольшого размера и обладать высоким быстродействием. Вызов функции контрольных точек осуществляется с помощью механизма прерываний, в частности, используется прерывание пользователя с номером 65. Функция контрольных точек выполняет измерение времени дважды: сразу после входа в нее и непосредственно перед выходом. Оба значения времени передаются измерительному монитору. После первого замера управление передается монитору и он выполняет действия по идентификации и накоплению результатов измерений. После возврата управления в функцию задания контрольных точек, выполняется второе измерение времени. Такой подход наиболее полно соответствует условиям 3 и 4, поскольку позволяет точно измерить не только время выполнения участка программы между контрольными точками, но и убрать временное искажение вносимое измерительным монитором.
Проведение измерительного эксперимента начинается с запуска монитора. Работа измерительного монитора состоит из нескольких фаз.
Ø Подготовительные операции. На этом этапе производится проверка допустимости входных параметров, формирование необходимых структур данных и операции по калибровке измерительного монитора. После окончания подготовительных операций управление передается исследуемой программе. Управление передается по схеме — «запуск программы-потомка с возвратом в предок».
Ø Идентификация и накопление измерительный информации. Эти действия производится после перехвата прерывания от исследуемой программы. Идентификация информации подразумевает не только анализ положения контрольных точек, но и определение ряда статистических сведений о проходах между контрольными точками. Накопление такого рода измерительной информации облегчает последующее формирование отчета и позволяет резко сократить расход памяти, потребляемой монитором. При накоплении измерительная информация корректируется для снятия временных искажений монитора. Таким образом, исследуемая программа выполняется без трассировки и освобождается от операций по анализу и протоколированию измерительной информации. Это полностью соответствует принципам 1, 2 и 4.
Ø Операции по анализу измерительной информации и формированию отчетов. Эта фаза является заключительной и наступает после окончания работы исследуемой программы. Реализация условия 5 требует значительных ресурсов ВС. В этой связи, целесообразно графическую интерпретацию снятого профиля выполнять в отдельной программе — просмотрщике. Снятый профиль программы выдается в виде текстового файла и в виде двоичного.
В «Sampler»e замеры системного времени проводятся, как и для IPM, внутри тестируемой программы вызовом функции задания точки профилирования. Этим достигается высокая точность измерения времени и отсутствие ограничений на использование отладочной информации и оптимизации компилятора. Функция задания точки профилирования определена в модуле на соответствующем языке программирования, подключаемом к тестируемой программе. С другой стороны, запуск тестируемой программы осуществляется, как и для Turbo Profiler, через монитор. Это позволяет освободить пользователя от сбора и классификации измерительной информации. Результаты измерения могут быть представлены как на экране компьютера, так и твердой копией после вывода протокола измерения на принтер.
ПИМ Sampler состоит из двух исполняемых модулей следующего функционального назначения:
v Измерительный монитор Sampler. Монитор запускает программу пользователя и перехватывает прерывания, несущие информацию о прохождении тестируемой программы пользователя через определяемые им точки (контрольные точки ). После отработки тестируемой программы, монитор выгружает собранную информацию в текстовый файл с профилем тестируемой программы и создает специальный двоичный файл для графической интерпретации результатов;
v Программа графической интерпретации результатов профилирования Smpview. Программа выдает снятый профиль на экран в максимально информативной форме. Такой формой является ориентированный граф с вершинами в контрольных точках снятия отсчетов. Программа анализирует схему переходов между контрольными точками и отображает ее в виде дуг графа. Информацию о времени перехода можно получить отметив нужные вершины на графе.
Обоснование методики измерения времени.
В ПИМ Sampler используются два режима измерения моментов времени, соответствующих выполнению фрагментов программы.
Режим 1: Измерения времени через 0 канал таймера с использованием портов ввода-вывода.
Для задания временных интервалов и формирования сигналов с различными временными параметрами в компьютерах IBM PC используется программируемый таймер 8253. Таймер работает независимо от процессора и считает реальное время. Формирование времени суток в компьютерах IBM PC можно пояснить схемой, показанной на рис.9.
IRQ0
Рис.9
Микросхема таймера имеет три канала, основным из которых с точки зрения измерения времени, является канал 0. Импульсы частотой 1.19 МГц от системных часов поступают на микросхему таймера, где происходит деление частоты на 64 К и на выходе канала 0 мы получаем импульсы с частотой 18,2 Гц ( с периодом следования 55 мс). Эти импульсы поступают на контроллер прерываний в виде запроса аппаратного прерывания на уровне 0 и, если разрешены прерывания, вырабатывается сигнал INT8.В результате обработки прерывания INT8 накапливаются данные в двойном слове с адресом 0040:006Сh, расположенном в области данных BIOS.
Более подробно возможность измерения временных характеристик программ с использованием микросхемы таймера можно пояснить с помощью рис.10.

Рис.10
Микросхема таймера содержит три канала с адресами 40h, 41h, 42h. Каждый канал содержит три регистра, два из которых двухбайтные — задвижка и счетчик и один — однобайтный — регистр ввода-вывода. Регистр ввода-вывода связан шиной с аккумулятором (регистром AL) для считывания информации.
Канал 0 таймера выполняет две функции:
1. Осуществляет контроль времени суток;
2. Синхронизирует дисковые операции (запись и считывание информации с магнитных носителей).
Если изменять заносимые в счетчик данные (не 0FFFF, а другие числа), то можно увеличить частоту выдачи импульсов на выходе таймера, но при этом могут наблюдаться сбои при выполнении дисковых операций.
Канал 1 таймера обеспечивает прямой доступ к памяти (DMA).
Канал 2 таймера служит для связи с периферийными устройствами, обеспечения выдачи звуковых сигналов.
Управление работой таймера осуществляется регистром команд по адресу 43h.
Структура команд порта по адресу 43h
| Канал 7 – 6 | Операция 5 – 4 | Режим 3-1 |
0 — бит указывает какая система счисления используется — двоичная или BCD — или двоично-кодированная десятичная.
Биты 1 — 3 задают режим работы таймера:
— 000 — запись данных счетчика в задвижку;
— 011 — выполнение основных операций по считыванию информации канала 0 и подсчета поступивших импульсов.
Биты 4 — 5 определяют возможные операции:
— 00 — передача данных из счетчика в задвижку или наоборот;
— 01 — чтение или запись старшего байта;
— 10 — чтение или запись младшего байта;
— 11 — чтение или запись последовательно младшего и старшего байтов.
При снятии измерений регистр задвижки загружается кодом (0FFFFh), который потом перемещается в счетчик. Счетчик считает поступающие тактовые импульсы в обратном направлении (в убывающем порядке), поэтому при его загрузке и считывании надо брать дополнение до FFFFFh. После того как счетчик обнулится, вырабатывается сигнал контроллера прерывания INT-8. Содержимое счетчика следует поместить в задвижку и считать его в аккумулятор AL. После этого восстановить содержимое задвижки и продолжить работу. Интервал времени в 1/18.2 сек (55 мс) получил название «тик», а минимально различимый интервал, равный 1/FFFF «тика» получил название «минитик» = 0.84 мкс.
Наиболее точное и полное значение промежутков времени можно получить, используя совместно значение переменной области данных BIOS (0040:006С) и внутреннего счетчика таймера. Это позволяет измерять промежутки времени длительностью от 0,84 мсек до 24 часов.
Достоинства режима измерения времени через 0 канал таймера с использованием портов ввода-вывода:
— возможность применения на машинах типа IBM PC любого класса.
Недостатки:
— низкая точность измерений;
— большая погрешность функции контрольных точек, обусловленная медленным снятием отсчетов времени через порты ввода-вывода.
Режим 2. Измерения времени через счетчик Time Stamp Counter (TSC).
Режим применяется только для старших моделей IBM PC, начиная с Pentium. В составе этих компьютеров появился внутренний 64 битный таймер, который может быть прочитан в регистры EDX:EAX с помощью инструкции RDTSC (Read Time Stamp Counter). Каждый такт этот счетчик увеличивает свое значение на 1. Это очень полезно для замера точного количества тактов, потребовавшихся на исполнение некоторого фрагмента кода.
К сожалению, имеются проблемы чтения содержимого счетчика TSC. В Pentium добавлен внутренний регистр CR4, флаг TSD которого управляет возможностью чтения счетчика TSC. При CR4.TSD, равном 0, счетчик TSC можно читать в любом случае. При CR4.TSD, равном 1, содержимое счетчика можно прочитать только на 0-ом уровне привелегий. В общем случае флаг CR4.TSD установлен. Поэтому, инструкция RDTSC не может выполняться в режиме виртуального 8086 (3-й уровень привилегий).
При использовании EMM386 или Windows процессор находится в защищенном режиме и Dos — приложения типа Sampler запускаются в виртуальном режиме и имеют 3 уровень привелегий. Поэтому, если запускать измеряемую программу под DOS, необходимо закомментировать EMM386 (или любой другой менеджер памяти) в CONFIG.SYS и не следует запускать программу в режиме DOS из под Windows.
Достоинства данного режима измерений:
— малая погрешность функций контрольных точек;
— высокая точность измерений (до нескольких машинных тактов):
— для регистрации отсчета времени требуется только команда RDTSC и сохранение регистров EAX:EDX (20-30 тактов).
Недостатки:
— возможность применения только на машинах класса Pentium и выше.
— возможность полноценной работы только под DOS и в отсутствие драйверов памяти типа EMM386 (QEMM).
§
Под корректностью программы понимают её соответствие некоторому эталону или совокупности формализованных эталонных правил и характеристик.
Наиболее полным эталоном корректности программ является программная спецификация. Её особенностью является задание требований поведения программы для допустимых наборов входных данных. Поэтому корректная программа может неправильно работать или даже сбиваться на недопустимых наборах входных данных. Свойством устойчивости к недопустимым наборам входных данных обладает надежная программа — в этом заключается разница между надёжной и корректной программами.
Требования к корректности делятся в зависимости от двух типов критериев качества:
· Для функциональных критериев они определяются предметной областью и функциями выполняемой программы.
· Для конструктивных критериев они определяются общими для всех программ свойствами.
В зависимости от проверяемых компонентов программ различают следующие виды их корректности, показанные на рис.11.

Рис.11
1. Корректность текстов программ имеет только конструктивную составляющую; благодаря жёстким правилам языков программирования синтаксическая и семантическая корректность программ проверяется на этапе трансляции программы, и прошедшая трансляцию программа является корректной с этой точки зрения.
2. Корректность программных модулей имеет и конструктивную и функциональную составляющие:
· Конструктивная составляющая определяется правилами построения структуры программных модулей, задаваемыми в технологии и языке программирования.
· Функциональная составляющая корректности модулей зависит от предметной области и функциональных спецификаций программы.
Функциональная составляющая корректности может проверяться в различных условиях:
Детерминированная — для фиксированных наборов входных данных должны быть получены конкретные значения результатов;
Стохастическая — входные данные задаются случайными величинами с известными законами распределения и результаты также должны быть случайными величинами с требуемыми законами распределения и заданными корреляционными связями между входными и выходными данными.
Динамическая — характерна для систем реального времени и определяется согласованием во времени порядка поступления входных данных и порядка выдачи результатов выполнения программы.
В общем случае функциональные спецификации программы определяют и функциональ-ные требования к программе, и характеристики, с которыми они должны обеспечиваться, как это показано на рис.12.

Рис.12
3.Корректность данных имеет конструктивную и функциональную составляющие.
Структурная корректность данных относится к конструктивной составляющей и предполагает правильность построения структурированных данных в программе: массивов, стеков, очередей и т.п. Функциональная корректность данных определяется диапазонами изменения их значений и соответствием типов полей структур типам значений данных.
4. Корректность комплексов программтакже имеет конструктивную и функциональную составляющие: конструктивная составляющая определяется корректностью структуры межмодульных связей по управлению и данным, определяемых в интерфейсных требованиях к программе; функциональной корректность комплекса программ определяется так же, как и функциональная корректность модулей.
II. Эталоны и методы проверки корректности.
Эталоны для проверки корректности программ могут использоваться в следующих трех формах, поясняемых с помощью рис.13:
1. Формализованные правила.
2. Программные спецификации.
3. Тесты.
Формализованные правила — имеют достаточно неопределенностей, так как опреде-ляются двумя видами требований:
* требования стандартов (общероссийских и стандартов предприятий);
* требования языков и технологий программирования.

Рис.13
Для полной убедительности в корректности программ одних формализованных правил недостаточно.
2. Программные спецификации — относятся к функциональным эталонам и в основ-ном обеспечивают проверку корректности программ в статике.
3. Тесты.
В зависимости от стадии и характера проверки разделяются тесты делятся на статические и динамические. Статическое тестирование — ручное тестирование программ, начиная со стадии формирования требований к программе. На стадии кодирования при статическом тестировании некоторую часть маршрутов исполнения тестируют вручную. Динамическое тестирование подразумевает достаточно полную структурную и функциональную проверку выполнения программы.
Как формируются эталоны для тестирования? Существует несколько способов формирования эталонов:
1) Использование аналитических выражений. Этот способ особенно подходит при детерминированном тестировании, так как имеется возможность сравнить результаты тестирования с ожидаемыми результатами. Имеются ограничения в использовании этого метода, если неизвестны или отсутствуют аналитические выражения связывающие входные данные и результаты; иногда требуется использовать много допущений.
2) Использование моделирования на ЭВМ. Способ является универсальным. При этом ряд данных моделируется другим способом и по другим алгоритмам, нежели испытываемая программа и на других ЭВМ. Причем наборы входных данных создаются по случайным законам, что обеспечивает высокую гибкость этого способа.
3) Использование результатов испытаний предшествующих вариантов программ.
При этом используется ранее накопленный опыт испытателя или других исследователей, выраженный в экспертных оценках ожидаемых результатов.
Степень достоверности проверки корректности программ при использовании этих методов убывает по номерам способов формирования эталонов.
В 1-ом случае обеспечивается 100% гарантия корректности программ, в третьем случае такой уверенности нет, но мы можем убедиться в том, что программа работает так же или иначе, чем аналогичный вариант. Менее достоверные тесты приходится использовать из-за недостаточности сил и средств.
§
Корректность является статическим свойством программы, поскольку она не зависит от времени (если, конечно, не изменяются цели разработки) и отражает специфику ошибок разработки программ (ошибок проекта и кодирования).
Различают два типа проверки корректности:
· валидация (validation) – установление соответствия между тем, что делает программа, и тем, что нужно Заказчику;
· верификация (verification) – установление соответствия между программой и ее спецификацией.
Определение верификацииисимметрично ввиду относительного характера свойства корректности: если программа не соответствует своей спецификации, то либо программа, либо спецификация, либо оба этих объекта содержат ошибки. Перефразируя известное изречение Э.Дейкстры о тестировании программ, можно сказать, что верификация способна доказать отсутствие ошибок в программе, но не всегда доказывает их присутствие.
В отличие от тестирования верификацияпредполагает аналитическое исследование свойств программыпоее тексту (без выполнения программы). Таким образом, для проведения верификации необходимо построить формально-логическую систему, в которой были бы формально определены свойства корректности программы. Для этих целей наиболее широкое применение получило исчисление предикатов первого порядка, расширенное аксиоматической арифметикой.
Можно сказать, что верификация – это вычисление истинности предикатаот двух аргументов: программы и спецификации. Истинность этого предикатаустанавливает свойство корректности программы, если спецификация не содержит ошибок, однако, его ложность, вообще говоря, не означает наличие ошибок в программе, а требует более точного разбора.
Учитывая специфику проявления ошибок в программах в процессе их выполнения на ЭВМ, целесообразно выделить в понятие корректности программы два свойства:
· частичную корректность – удовлетворение внешним(входной и выходной) спецификациямпрограммы при условии завершения выполнения программы;
· завершенность – достижение в процессе выполнения выхода программыпри определенных входной спецификацией данных.
Свойство завершенностине является тривиальнымдля такого объекта, как программа, ввиду возможности циклических и рекурсивных вычислений, а также наличия частично-определенных операций. Случаи, когда свойство завершенности не удовлетворяется, довольно обычны для программ с ошибками, и приводят к заведомо некорректным программам независимо от спецификации выхода.
Каждое из двух выделенных свойств корректности программы может удовлетворяться или не удовлетворяться. Таким образом, можно выделить шесть основных задач анализа корректности программы:
· частичная корректность (при условии завершенности);
· завершенность программы;
· незавершенность программы;
· тотальная корректность (частичная корректность и завершенность);
· частичная некорректность (некорректность при условии завершенности);
· некорректность (незавершенность или частичная некорректность).
Разделение свойств частичной корректности и завершенности следует рассматривать как методологический прием, направленный на уменьшение сложности верификации программ.
Рассмотрим формальные постановки задач анализа корректности.
Введем ограничение: будем рассматривать программы, начинающиеся оператором START(первый выполняемый оператор) и заканчивающиеся оператором STOP(последний выполняемый оператор).
Спецификацию программы Prgm будем определять путем приписыванияиндуктивных утвержденийточкам разреза графа потоков управления программы (точкам между операторами программы). При этом выходу оператораSTARTприписываетсявходной предикат (предусловие) программы P(x), определяющий множество допустимых значений исходных данныхx(xдопустимо, еслиP(x): true), а входу оператора STOPприписываетсявыходной предикат (постусловие) Q(x,y), определяющий целевую функцию программы (связь между входными и выходными данными программы).
Тогда свойство частичной корректности программы определяется следующей формулой логики предикатов:
PCOR(Prgm, P, Q): «x ( P(x) Ù fin(x) Þ Q( x, f(x) ) ),
где fin(x) –предикат завершения программыPrgm, начатой в состоянииx;
f(x) –функция, вычисляемая программойPrgm,
свойство завершенности может быть определено формулой:
FIN(Prgm, P): «x ( P(x) Þ fin(x) ),
а свойство тотальной корректности формально выражается как одновременное присутствие свойств частичной корректности и завершенности:
TCOR(Prgm, P, Q): «x ( P(x) Þ Q(x, f(x) ) Ù fin(x) ).
Аналогичным образом могут быть формализованы и другие перечисленные выше свойства корректности (записать самостоятельно).
Заметим, что для произвольных программ каждое из этих свойств (завершенность и частичная корректность) является алгоритмически неразрешимым, т.е. не существует алгоритма, позволяющего оценить истинность соответствующих формул логики предикатов. Однако для отдельных классов программ в настоящее время разработаны достаточно эффективные методы верификации, позволяющие вручную или автоматически проводить соответствующие доказательства. Такие методы могут рассматриваться как составная часть процессов разработки и отладки программ, обеспечивая логическую завершенность этих процессов.
Наиболее распространенным методом доказательства частичной корректности программ является метод индуктивных утверждений, предложенный Флойдом. Он позволяет свести доказательство частичной корректности программы к доказательству некоторого конечного числа утверждений, записанных на языке исчислений предикатов первого порядка и имеющих интерпретацию в соответствующей проблемной области.
Рассмотрим метод индуктивных утверждений для программ с конечным множеством простых переменных { x1, x2, … xn }, где n³1, а операторами являются:
· операторы присваивания вида xi := f (x1, x2, … xn);
· составной оператор вида A ; B;
· оператор условного переходаif a(x1, x2, … xn) then L else L–,
где L ,L– – метки операторов, которым передается управление;
· начальный оператор START;
· конечный оператор STOP.
Такой состав структурных компонентов вполне достаточен для представления произвольного алгоритма и поэтому не ограничивает общности излагаемого метода.
Установление частичной корректности осуществляется за четыре последовательных шага.
Шаг 1.Разрезание циклов программы
Очевидно, что при выполнении программы для различных исходных данных возможны различные последовательности операторов, начинающиеся оператором STARTи оканчивающиеся оператором STOP. Назовем такие последовательности трассами вычислений.
Сложность анализа частичной корректности программы разбиением на трассы заключается в том, что при наличии циклов в программе он не может быть выполненнепосредственным перебором всех трасс. Эта сложность может быть преодолена путем включения в граф потока управления программы конечного числа точек, называемых точками разреза, таким образом, что каждый цикл содержитодну такую точку, которая “разрезает” циклические пути на два:
· путь через тело цикла;
· путь к выходу из цикла.
§
Введенное понятие условия Uaмежду соседними контрольными точками позволяет свести задачу анализа частичной корректности программы Prgm к доказательству истинности условий между любыми соседними контрольными точками программы Prgm.
Теорема (без док-ва). Программа Prgm частично корректна относительно предусловия P и постусловия Q, если для каждого пути a между соседними контрольными точками условие пути Uaистинно.
Важность этой теоремы состоит в том, что она позволяет абстрагироваться от конкретных процессов между соседними контрольными точками вычислений по программе и рассматривать только условия Ua между соседними контрольными точками, т.е. рассматривать толькохарактеристики статической структуры программы.
Возможности доказательства условий корректности Ua зависят от проблемной области.
Пример
Доказать частичную корректность программы вычисления частного и остатка от деления целых чисел xи y.
Программа на Паскале:
r := x; q := 0;
while y £ r do
begin r := r – y; q := q 1 end
Блок-схема этой программы имеет вид:
1. Разрезание цикла программы.
Разрежем цикл программы в точке входа в цикл (точка t3)..
2. Получение аннотированной программы.
Запишем индуктивные утверждения для программы в контрольных точках t1, t2 и t3.
P: invt1( x,y ) º ( x ³ 0 ) Ù ( y > 0 );– условие корректных исходных данных
Q: invt2 ( x,y, q,r ) º ( x = r y*q ) Ù ( r < y ); –условие выхода из цикла
invt3 ( x,y, q,r ) : x = r y*q– инвариант цикла.
3. Определение набора условий корректности для всех путей между соседними контрольными точками программы.
Путями между контрольными точками являются:
a1 :от входа программы к началу цикла (t1 – t3);
a2 :от начала цикла через тело цикла обратно к началу цикла (t3 – t3);
a3 :от начала цикла через условие цикла к выходу программы (t3 – t2).
Тогда
Ua1 : P Þ invt3 ( r x, q 0 ) º
( x ³ 0 ) Ù ( y > 0 ) Þ x = x y*0 º
( x ³ 0 ) Ù ( y > 0 ) Þ x = x º
( x ³ 0 ) Ù ( y > 0 ) Þ true
Ua2 : invt3 ( x,y, q,r ) Þ
( ( y £ r ) Þ invt3 ( x,y, q q 1, r r – y) ) º
(x = r y*q ) Þ ( ( y £ r ) Þ ( x = ( r — y ) y*(q 1))) º (x = r y*q ) Þ ( ( y £ r ) Þ (x = r y*q ) );
Ua3 : invt3 ( x,y, q,r ) Þ ( ( y > r ) Þ Q ) º
(x = r y * q ) Þ ( ( y > r ) Þ (x = r y * q ) Ù ( r < y ) )
4. Доказательство истинности условий Ua.
Условие Ua1– истина, так как x1 Þ x2 – тождественная истина, еслиx2 – истина.
Преобразуем условие Ua2.
(x = r y * q ) Þ ( ( y £ r ) Þ (x = r y * q ) ) º
( (x = r y * q ) Ù ( y £ r ) ) Þ (x = r y * q ) ) º
Ø( (x = r y * q ) Ù ( y £ r ) ) Ú ( x = r y * q ) º
Ø( x = r y * q ) Ú Ø( y £ r ) Ú ( x = r y * q ) º
Ø( y £ r ) Ú true º ( y £ r ) Þ true.
Следовательно, Ua2 – истина (по аналогии с Ua1).
Преобразуем условие Ua3.
(x = r y * q ) Þ ( ( y > r ) Þ (x = r y * q ) Ù ( r < y ) ) º
(x = r y * q ) Ù ( y > r ) Þ (x = r y * q ) Ù ( r < y ) º
( y > r ) Þ ( r < y ), так как x = r y * q– true.
Следовательно, Ua3 – истина
Таким образом, доказана истинность всех трех условий корректности и. следовательно, установлено свойство частичной корректности программы.
Пример 2
 Доказать частичную корректность программы вычисления z = [Öx]для любого целого x ³ 0. [Öx]есть наибольшее целое число k такое, что k £ Öx.
Доказать частичную корректность программы вычисления z = [Öx]для любого целого x ³ 0. [Öx]есть наибольшее целое число k такое, что k £ Öx.
Решение
Метод вычисления, на котором основана программа, основывается на известном соотношении: 1 3 5 … (2k 1) = (k 1)2для каждого k ³ 0.
Пусть значение суммы запоминается в s, а нечетные числа 2k 1 –в n.
Программа на Паскале:
k := 0; s:= 0; n:= 1;
s := s n;
while x £ s do
begin k := k 1; n := n 2;
s := s n;
end;
z := k;
Блок-схема этой программы имеет вид:

1. Разрежем цикл программы в точке B.
2. Получение аннотированной программы.
Запишем индуктивные утверждения для программы в контрольных точках A, B и C.
P: invA(x) º x³0 ;– условие корректных входных данных
Q: invС ( x,z ) º (z2 £ x) Ù ( x < (z 1)2 ); –условие выхода из цикла
invB (x,k, s,n): ( k2£x ) Ù ( s= (k 1)2 ) Ù ( n=2k 1 )– инвариант цикла.
Определение набора условий корректности для всех путей между
соседними контрольными точками программы.
Путями между контрольными точками являются:
a1 :от входа программы к точке разреза цикла (A – B);
a2 :от точки разреза цикла через тело цикла обратно в точку разреза цикла (В – B);
a3 :от точки разреза цикла через условие цикла к выходу программы
(B – C).
Тогда
Ua1 : P Þ invB (x,k, s s n,n) º
( x ³ 0 ) Þ (k2 £ x ) Ù ( s n = (k 1)2 ) Ù ( n=2k 1 ) ) º
( x ³ 0 ) Þ ( 02 £ x ) Ù (0 1 = (0 1)2) Ù ( 1=2*0 1 ) ) º
( x ³ 0 ) Þ ( ( 02 £ x ) Ù (1 = 1) Ù (1 = 1) );
Ua2 : invB (x,k, s,n) Þ ((s£x) Þ
invB(x,k k 1, s s n, n n 2)) º
( k2 £ x ) Ù ( s = (k 1)2 ) Ù ( n=2k 1 ) Þ ((s£ x) Þ
( (k 1)2 £ x ) Ù ( s n 2 = (k 2)2 ) Ù ( (n 2) = 2*( k 1) 1) );
Ua3 : invB (x,k, s,n) Þ ( ( s £ x ) Þ invС ( x,z k) ) º
( k2 £ x ) Ù ( s = (k 1)2 ) Ù ( n=2k 1 ) Þ ( ( s > x ) Þ
(k2 £ x) Ù ( x < (k 1)2 )
Доказательство истинности условий Ua.
Истинность всех трех условий легко проверяется подстановкой.
4.1. Условие Ua1– истина, так как
выражение( x ³ 0 ) Þ ( ( 02 £ x ) Ù (1 = 1) Ù (1 = 1) ) º
(x ³ 0) Þ (0 £ x) º Ø(x ³ 0) Ú (0 £ x) º (x < 0) Ú (x ³ 0) º true
4.2. Преобразуем условие Ua2.
( k2 £ x ) Ù ( s = (k 1)2 ) Ù ( n=2k 1 ) Þ ( (s £ x) Þ
( (k 1)2 £ x ) Ù ( s n 2 = (k 2)2 ) Ù ( (n 2) = 2( k 1) 1) ) º
( ( k2 £ x ) Ù ( s = (k 1)2 ) Ù ( n=2k 1 ) Ù (s £ x) ) Þ
( (k 1)2 £ x ) Ù ( s n 2 = (k 2)2 ) Ù ( (n 2) = 2( k 1) 1) )
Для доказательства истинности условия Ua2 нужно показать, что соотношения, образующие конъюктивные члены справа от знака импликации, следуют из соотношений, стоящих слева от знака импликации.
а) Поскольку x ³ sи s = (k 1)2, то (k 1)2 £ x.
б) s n 2 = (k 1)2 2k 1 2 º k2 2k 1 2k 1 2 = (k 2)2
в) n 2 = 2 (k 1) 2 = 2 (k 1) 1
Следовательно, условие истинно.
4.3. Преобразуем условие Ua3.
( k2 £ x ) Ù ( s = (k 1)2 ) Ù ( n=2k 1 ) Þ ( ( s > x ) Þ
(k2 £ x) Ù ( x < (k 1)2 ) º
( k2 £ x ) Ù ( s = (k 1)2 ) Ù ( n=2k 1 ) Ù ( s > x ) Þ
(k2 £ x) Ù ( x < (k 1)2 )
Поскольку s > xи s = (k 1)2, то (k 1)2 > xи Ua3 – истина
§
Особенность свойства завершенности программ состоит в том, что оно не зависит от постусловия программы, и для заданной программы полностью определяется предусловием. В общем случае формальный анализ свойства завершенности представляет весьма сложную проблему.
Имеются по меньшей мере две причины, по которым программа с заданным предусловием P может не завершиться:
· обращение к частично определенной функции со значением аргументов вне области определения;
· зацикливание.
Первая причина может приводить к аварийному завершению даже нециклических программ (например, при делении на нуль). Вторая причина присуща программам с итеративными циклами.
Ограничимся рассмотрением методов анализа завершения циклических вычислений без учета других возможных причин незавершения, т.е. предполагается, что любой нециклический оператор завершается и передает управление на его выход.
Наибольшее распространение получили два метода логического анализа завершения циклических вычислений:
· метод Флойда;
· метод счетчиков.
Метод Флойда
Этот метод может рассматриваться как дальнейшее развитие метода индуктивных утверждений. Основная идея метода состоит в том, чтобы с каждой контрольной точкой программы, лежащей на циклическом пути, связать некоторую частичную функцию, значения которой ограничены.
Для формализации этой идеи в достаточно общей форме введем понятие фундированного множества.
Пусть S – частично упорядоченное множество относительно бинарного отношения #на его элементах, т.е. на множестве Sдля a, bи с Î Sвыполняются свойства:
· антирефлексивности Ø(a # a);
· антисимметрии a # b Þ (Ø(b # a));
· транзитивности a # b Ù b # c Þ a # c.
Множество Sназывается фундированным, если не существуетбесконечной убывающей последовательности элементов из S.
Примеры фундированных множеств:
· множество натуральных чисел с отношением <;
· множество S* всех слов в алфавите S, включая пустое слово с отношением w1 < w2, означающим что w1 есть собственное подслово w2.
Пусть Prgm – аннотированная программа, для которой методом индуктивных утверждений доказана частичная корректность. С каждой контрольной точкой r, лежащей на циклическом пути ( для этой точки существует обратный путь в точку r), свяжем частичную (ограничивающую) функцию yr (x1, … , xn), принимающую значения в фундированном множестве S.
Для каждого пути aмежду парой соседних контрольных точек rи t(rможет совпадать с t), лежащих на циклическом пути, определим условие завершения в виде
Wa: ( invr(x1, …, xn) Þ (Ûa(x1, …, xn)) Þ (yr(x1, …, xn)ÎS Ù
yt(ja(x1, …, xn))ÎS Ù yr(x1, …, xn) ~yt(ja(x1, …, xn))))),
где Ua: invr(x1, …, xn) Þ (Ûa(x1, …, xn)) Þ invt(ja(x1, …, xn))– условие корректности метода индуктивных утверждений, ja –обратное преобразование, осуществляемое на пути aв методе индуктивных утверждений, т.е.
U0 = Ûa(x1, …, xn)Þ invt(ja(x1, …, xn)), где (yr –ограничивающая функция видаX1´ X2´ …´ Xn ® S, приписанная точке r.
Для доказательства завершенности программы методом Флойда может потребоваться усиление инвариантов, используемыхв доказательстве частичной корректности. В целом успех доказательства в значительной мере предопределяется искусством выбора ограничивающих функций y.
Метод счетчиков
Идея этого метода состоит во введении в программу Prgm новых переменных-счетчиков, добавляемых по одной в каждый цикл программы. Переменная-счетчик должна инициализироваться перед входом в цикли увеличивать свое значение при каждом прохождении по циклу.
В преобразованной таким образом программе Prgm’ измененные инварианты циклов представляются в виде, содержащем условие ограниченности значений счетчиков функциями, зависящими только от входных переменных.
В отличие от метода Флойда этот метод не требует введения ограничивающих функций в контрольных точках. Переменные-счетчики рассматриваются как органическая часть программы, позволяющая логически выразить свойство завершенности в инвариантах цикла.
Преимущество этого метода перед методом Флойда состоит в том, что одни и те же инварианты используются при доказательстве частичной корректности и завершенности. Однако метод Флойдаобладает большей общностью.
Успех доказательства завершенности в методе счетчиков определяется тем, удастся ли подобрать соответствующее условие ограниченности счетчика в инварианте цикла.
Этот метод, так же как и метод Флойда, требует творческого подхода программиста.
§
Основные понятия процесса тестирования
Тестироваться могут самые разные представления знаний о разрабатываемой или сопровождаемой программе на любой фазе ее жизненного цикла. Это могут быть требования к программному продукту, cпецификации проекта или структур данных, фрагменты программного кода.
В литературе имеется несколько различных определений понятия “тестирование”. Будем использовать следующее:
Определение. Тестирование –это контролируемое выполнение программы на конечном множестве наборов данных и анализ результатов этого выполнения с целью обнаружения ошибок.
Часто тестирование программы в соответствии с этим определением называют динамическим тестированием, а статический анализ, не требующий выполнения программы (просмотр, инспекция), – статическим тестированием.
Принято выделять методы тестирования и критерии тестирования программного продукта.
Определение. Методы тестирования – это совокупность правил, регламентирующих последовательность шагов по тестированию.
Определение. Критерии тестирования – соображения, позволяющие судить о достаточности проведенного тестирования.
Под ошибкой принято понимать различие между вычисленным, обозреваемым или измеренным значением или условием и действительным, специфицированным или теоретически корректным значением или условием, т.е. в программе имеется ошибка, если ее выполнение не оправдывает ожиданий пользователя.
Любой программный продукт – от простейших приложений до сложных комплексов реального времени, – вряд ли можно считать свободным от ошибок.
Результативным (удачным) считается тест, прогон которого привел к обнаружению ошибки. Из данного свойства теста вытекает важное следствие: тестирование – процесс деструктивный (обратный созидательному, конструктивному). Именно этим объясняется, почему многие считают его трудным. Большинство людей склонны к конструктивному процессу созидания объектов и в меньшей степени – к деструктивному процессу.
При существующих в реальной работе ограничениях на время, стоимость, надежность и т.п. разработки программного продукта ключевым являетсяследующий вопростестирования: Какое подмножество всех возможных тестов имеет наивысшую вероятность обнаружения большинства ошибок?
Определение. Тест – это набор входных значений, условий выполнения и ожидаемых значений на выходе, разработанных для проверки конкретного пути выполнения программы.
Программный продукт, как объект тестирования, имеет ряд особенностей, которые отличают процесс тестирования программного обеспечения от традиционного, исторически ранее появившегося “аппаратного” тестирования:
· отсутствиеполностью определенного единого эталона, которому должны соответствовать все результаты тестирования проверяемой программы;
На практике для тестирования используются в качестве эталонов косвенные данные, которые не полностью отражают функции и характеристики программ.
· высокая сложность программ и принципиальная невозможность построения тестовых наборов, достаточных для исчерпывающего тестирования;
Комплексы программ, используемые для управления и обработки информации, являются одними из самых сложных изделий, создаваемых человеком. При существующей сложности программ недостижимо исчерпывающее их тестирование, гарантирующее абсолютно полную проверку. Поэтому тестирование проводится в объемах, минимально необходимых для проверки программ в некоторых ограниченных пределах изменения параметров и условий функционирования. Ограниченность ресурсов тестирования привела к необходимости тщательного упорядочивания применяемых методов и конкретных значений параметров с целью получения при тестировании наибольшей глубины проверок программ. Это определяет необходимость применения экономичных и эффективных методов тестирования.
· наличие в программах вычислительных и логических компонент, а также компонент, характеризующихся стохастическим и динамическим поведением;
В сложных программных комплексах практически всегда имеются компоненты, осуществляющие преобразования данных. Кроме того, значительную часть программ составляют схемы принятия логических решений, обработки логических и символьных переменных. В ряде случаев процесс исполнения программ и получаемые результаты зависят от случайного изменения входных и промежуточных данных, а также от реального времени.
· относительно невысокая степень формализации критериев завершения процесса тестирования и оценки качества тестирования.
Показатели качества сложных комплексов программ трудно формализуются и еще более трудно измеряются. Вследствие этого качество процесса тестирования программ и достигаемая при этом их корректность остаются весьма неопределенными и незарегистрированными. Оценки полноты тестирования и достигаемого при этом качества программ обычно получаются в процессе испытаний и сопровождения программ.
Подытоживая перечисленные выше особенности тестирования программного продукта, необходимо подчеркнуть невозможность создания единственного универсального метода тестирования.
На практике приходится применять ряд значительно различающихся методов и критериев тестирования. Каждая категория тестовотличается целевыми задачами тестирования, проверяемыми компонентами программ и методами оценки результатов. Только совместное и систематическое применение различных методов тестирования и категорий тестов, базирующихся на различных критериях тестирования, позволяет достичь высокого качества функционирования средних и сложных программных комплексов со средней или большой длительностью эксплуатации, имеющих большой размер исходного кода (105 — 107 строк в программе).
Сформулируем основные принципы тестирования:
· Описание предполагаемых значений выходных данных или результатов должно быть неотъемлемой частью теста.
· Следует избегать тестирования программы ее автором; тестирование является более эффективным, если оно выполняется не автором программы, но отладка программы обычно более эффективно выполняется авторами.
· Организацияне должна сама тестировать разработанные ею программные продукты.
· Необходиимо досконально изучать результаты применения каждого теста.
· Тесты для неправильных и непредусмотренных входных данныхследует разрабатывать так же тщательно, как для правильных и предусмотренных данных.
· Необходимо проверять программу на нежелательные побочные эффекты.
· Не следует выбрасывать тесты, даже если программа уже не нужна.
· Нельзя планировать тестирование в предположении, что ошибки не будут обнаружены.
· Вероятность наличия необнаруженных ошибок в части программы пропорциональна числу ошибок, уже обнаруженных в этой части.
§
Известно, что существует несколько различных моделей жизненного цикла программного обеспечения, отличающихся друг от друга некоторыми деталями. При этом представление программы на разных фазах ЖЦ изменяется в соответствии с поэтапным изменением программ от уровня первичных целей и алгоритмов до уровня завершенного эксплуатируемого и сопровождаемого программного продукта.
С точки зрения тестирования наиболее значимыми являются следующие объекты программного проекта:
· спецификации программных модулей, групп программ и программных комплексов;
· программные модули (код программных модулей);
· группы программ, решающие законченные функциональные задачи;
· комплексы программ, для которых завершены все виды отладки;
· программные средства, подлежащие испытаниям перед сдачей в эксплуатацию;
· сопровождаемый программный продукт до завершения его жизненного
цикла.
Эти объекты различаютсясложностью тестирования, уровнем теоретической разработки методов и существующей степенью автоматизации процесса тестирования.
Состояние теории и практики тестирования можно изобразить следующим графиком (нумерация объектов на рисунке соответствует списку объектов тестирования):

1 2 3 4 5 6
Спецификации Модули Группы Комплексы Прогр. Программный
программ программ ср-ва продукт
Приведенные графики имеют только иллюстративное значение и имеют целью показать общее состояние теории и практики тестирования.
Наиболее формализованным является тестирование спецификаций, которые содержат “наименьшее количество информации” о программах среди всех рассматриваемых объектов. По мере перехода от модуля к группе и комплексу программ сложность тестирования каждого отдельного объекта быстро возрастает. Тестирование ПО при комплексной отладке, испытаниях и сопровождении по степени сложности примерно одинаково. Следует отметить, что интегральная сложность (и, соответственно, трудоемкость) тестирования всей совокупности программных модулей, входящих в комплекс, может быть выше, чем сложность тестирования при испытаниях и сопровождении
Уровень теоретической разработки методов тестирования значительнозависит от объектов. Наиболее полно в настоящее время исследованы методы тестирования программных модулей и небольших групп программ, написанных с использованием процедурных языков программирования. Менее исследованными остаются методы и теория тестирования групп программ, написанных с использованием объектно-ориентированных языков программирования. Мало исследованными являются методы и теория тестирования в процессе отладки, испытаний и сопровождения крупных комплексов программ.
Степень автоматизации тестирования или, точнее, относительные затраты на его обеспечение значительно возрастают по мере увеличения сложности объектов тестирования. Автоматизация тестирования отстает от потребностей практики. Наиболее автоматизированотестирование модулей и групп программ, написанных с использованием процедурных языков программирования.
§
§
Остановимся более подробно на критериях и методах тестирования программных модулей и групп программ, решающих законченные функциональные задачи.
При этом будут рассматриваться следующие виды тестирования:
· модульное – проверка корректности структуры модулей и их основных конструктивных компонент (циклов, блоков, разветвлений), функций и данных (входных и выходных);
· интеграционное – проверка корректности управляющих и информационных связей между модулями. При проведении интеграционного тестирования важным является порядок сбора модулей в единую программу. Существует два основных подхода к комбинированию модулей:
¨ пошаговое – каждый модуль подключается к набору ранее оттестированных модулей (сверху вниз или снизу вверх);
¨ монолитное – все модули одновременно объединяются в программу;
· системное – проверка соответствия интегрированной в единое целое программной системы спецификациям с учетом среды и режима выполнения;
Модульное и интеграционное тестирование основаны на структурных методах (принцип «белого ящика»). При применении этих методов существенно используются знания о структуре программы вне зависимости от того, является ли она отдельным модулем или группой модулей. При структурном тестировании всегда существует модель, отражающая логику работы программы и критерий проведения тестирования, причем количество необходимых тестов при этом ограничено.
При проведении системного тестирования используется методология функционального тестирования (принцип «черного ящика), в которой для построения тестов не используется информация о структуре программы, а используются ее функциональные спецификации.
При функциональном тестировании средних и больших программных проектов трудно предложить правила, ограничивающие необходимый объем тестирования, т. к. системное тестирование включает в себя множество категорий тестов, в том числе тесты для проверки:
· функциональности программы;
· работы на предельных объемах;
· работы на предельных нагрузках;
· удобства эксплуатации программы;
· защиты от несанкционированного доступа;
· производительности;
· требований к памяти;
· конфигураций оборудования;
· совместимости;
· удобства инсталляции;
· надежности;
· восстановления при сбоях;
· документации на программу.
Деление методов тестирования на функциональные и структурные производится в зависимости от источника тестовых данных. Как правило, структурное и функциональное тестирование хорошо сочетаются, так что для каждого структурного теста существует его точная функциональная интерпретация.
Остановимся более подробно на этих методах тестирования.
§
При проведении структурного тестирования на основе управляющего графа программы используются следующие критерии:
· покрытие операторов (вершин графа) – заключается в выполнении каждого оператора программы хотя бы один раз. Этот критерий является весьма слабым (пропускает много ошибок), так как выполнение каждого оператора программы хотя бы один раз есть необходимое, но не достаточное условие для приемлемого тестирования по методу “белого ящика”;
· покрытие ветвей (решений) – при использовании этого критерия каждая дуга должна быть пройдена хотя бы один раз. Критерий покрытия решений обычно удовлетворяет критерию покрытия операторов, поскольку каждый оператор лежит на некотором пути.
· покрытие условий – каждое логическое условие в программе должно выполняться хотя бы один раз.
· покрытие условий/решений – поскольку критерии покрытия решений и условий не заменяют друг друга, поэтому их можно объединить, получив критерий покрытия условий/решений. Он требует такого набора тестов, чтобы все возможные результаты каждого условия в решении выполнялись по крайней мере один раз и все результаты каждого решения выполнялись по крайней мере один раз. Недостатком критерия покрытия решений/условий является невозможность его применения для выполнения всех результатов всех условий (некоторые условия могут быть скрыты другими условиями). Например, результаты условий при выполнении операций И и ИЛИ могут блокировать действия других условий. Так, если условие Иесть ложь, то никакое из последующих условий в выражении не будет выполнено. Аналогично, если условие ИЛИестьистина, то никакое из последующих условий в выражении не будет выполнено.
· комбинаторное покрытие условий – требует такого набора тестов, чтобы все возможные комбинации результатов условия в каждом решении выполнялись по крайней мере один раз. Слово возможные употреблено потому, что не все комбинации условий могут быть реализуемыми; например, в выражении (A>2) & (A<10) могут быть реализованы только три комбинации условий. Набор тестов, удовлетворяющий критерию комбинаторного покрытия условий, удовлетворяет также и критериям покрытия решений, покрытия условий и покрытия решений/условий;
· покрытие путей – каждый путь хотя бы один раз (это наиболее полный, но нереализуемый критерий);
· покрытие функций — каждая функция должна быть выполнена хотя бы один раз;
· покрытие вызовов – каждый вызов каждой функции хотя бы один раз.
Пример
if ( (A > 1) & ( B=0 ) ) then X:=X/A;
if ( (A = 2) Or ( X>1 ) ) then X:=X 1;
1) Покрытие операторов
a) Можно выполнить каждый оператор с помощью теста, который бы реализовал путь ace (A=2; B=0; X=3):
· Если в программе записано (A>1) OR (B=0) – Ошибка не обнаруживается!
· Если в программе (A=2) ! (X>0) – Ошибка не обнаруживается!
b) На пути abd все ошибки не обнаруживаются!
Покрытие ветвей
Покрытие решений может быть реализовано двумя тестами, покрывающими либо пути ace и abd, либо пути acdи abe. Если выбрать второе покрытие, то входами двух тестов являются: A=3; B=0; X=3(путь acd) и A=2; B=1; X=1(путь
abe). Эти тесты также недостаточны. Например, если выбрано первое покрытие (путь acd),путь, где Xне изменяется, будет проверен с вероятностью 50%. Если во втором условии имеется ошибка (например, X<1вместо X>1), то эта ошибка тестами не будет обнаружена!
Покрытие условий
В программе имеются 4 условия: A > 1, B = 0, A = 2 и X > 1. Следовательно, требуется достаточное число тестов, чтобы реализовать ситуации, где A>1, A£1, B=0 и B¹0 (первое условие) и A=2, A¹2, X>1, X£1(второе условие). Тесты, удовлетворяющие критерию покрытия условий, и соответствующие им пути:
· A=2; B=0; X=4(путь ace);
· A=1; B=1; X=1(путь abd)
Критерий покрытия условий обычно лучше критерия покрытия решений, поскольку оно может вызвать выполнение решений в условиях, не реализуемых при покрытии решений.
С другой стороны, критерий покрытия условий может не удовлетворять критерию покрытия решений. Для рассмотренного примера предложенные тесты покрытия условий покрывают результаты всех решений, но это случайное совпадение. Например, два альтернативных теста: A=1, B= 0, X=3 и
A=2, B=1, X=1покрывают результаты всех условий, но только два из четырех результатов решений (оба они покрывают путь abeи, следовательно, не выполняют результат истина первого решения и результат ложь второго решения).
§
Цель – выбрать минимальное подмножество тестов, обеспечивающих наибольшую вероятность обнаружения ошибок.
Правильно выбранный тест этого подмножества должен обладать двумя свойствами:
1) включать как можно больше входных условий с тем, чтобы минимизировать общее число тестов;
2) разбивать входные данные программы на конечное число классов эквивалентности так, чтобы можно было предположить, что если один тест класса эквивалентности обнаруживает ошибку, то следует ожидать, что и все другие тесты этого класса эквивалентности будут обнаруживать ту же самую ошибку и, наоборот, если тест не обнаруживает ошибки, то следует ожидать, что ни один тест этого класса не будет обнаруживать ошибки (в том случае, когда некоторое подмножество класса эквивалентности не попадает в пределы другого класса эквивалентности, так как классы эквивалентности могут пересекаться).
Разработка тестов методом эквивалентного разбиения осуществляется в два этапа:
1) выделение классов эквивалентности;
2) построение тестов.
1.1. Выделение классовэквивалентности
Классы эквивалентности выделяются путем выбора каждого входного условия (предложение спецификации) и разбиения его на две или более групп.
Различают два типа классов эквивалентности:
· правильные классы эквивалентности, представляющие правильные входные данные программы;
· неправильные классы эквивалентности, представляющие ошибочные входные данные.
Выделение классов эквивалентности представляет собой взначительной степени эвристический процесс. Однако существует ряд правил, которые следует выполнять:
1) Если входное условие описывает область значений (например, 1 £ I £ 100), то задается один правильный класс эквивалениности (1 £ I £ 100)и два неправильных ( X < 1 и X>100).
2) Если входное условие описывает число значений (например, число элементов последовательности N не должно превышать 10), то определяется один правильный класс эквивалентности (N £ 10)и два неправильных (N<1 и N>10).
3) Если входное условие описывает множество входных значений и есть основание полагать, что каждое значение программа трактует особо (например, цвет может принимать значения: красный, желтый, зеленый), то определяется правильный класс эквивалентности для каждого значения и один неправильный класс эквивалентности – значение, не принадлежащее множеству (например, белый).
4) Если входное условие описывает ситуацию “должно быть” (например, первым символом идентификаторадолжна бытьбуква), то определяется один правильный класс эквивалентности (первый символ – буква) и один неправильный класс эквивалентности (первый символ – не буква).
5) Если есть основание считать, что различные элементы класса эквивалентности трактуются программой неодинаково, то данный класс эквивалентности разбивается на меньшие классы эквивалентности.
Построение теста
1) Назначениекаждому классу эквивалентности уникального номера.
2) Проектирование новых тестов, каждый из которых покрывает как можно большее числонепокрытых правильных классов эквивалентности, до тех пор пока все правильныеклассы эквивалентности не будут покрыты.
3) Запись тестов, каждый из которых покрывает один и только одиниз непокрытых неправильных классов эквивалентности, до тех пор пока все неправильные классы эквивалентности не будут покрыты. Причина покрытия неправильных классов эквивалентности индивидуальными тестами заключается в том, что определенные проверки с ошибочными входами скрывают или заменяют другие проверки с ошибочными входами.
§
Граничные условия – это ситуации, возникающие непосредственно на, выше или ниже границ входных и выходных классов эквивалентности.
Анализ граничных значений отличается от эквивалентного разбиения в двух отношениях:
1. Выбор любого элемента в классе эквивалентности в качестве представительного при анализе граничных значений осуществляется таким образом, чтобы проверить тестом каждую границу этого класса (т.е. исследуются ситуации, возникающие на и вблизи границ эквивалентных разбиений).
2. При разработке тестов рассматривают не только входные условия, но и выходные значения.
Правила использования данного метода:
1) Построить тесты для границ области и тесты с неправильными входными данными для ситуаций незначительного выхода за границы области, если входное условие описывает область значений. Например, если правильное значение —1.0 £ X £ 1.0, то составить тесты для ситуаций: —1.0, 1.0, -1.001, 1.001.
2) Построить тесты для минимального и максимального значений условий и тесты, большие и меньшие этих значений, если входное условие принимает значения из некоторого дискретного диапазона. Например, если входной файл может содержать от 1 до 256 записей, то необходимо составить тесты для 0, 1, 255 и 256 записей.
3) Использовать правило 1) для каждого выходного условия. Например, если программа вычисляет ежемесячный расход и если минимум расхода составляет 0.00 руб., а максимум – 100000.00 руб, то нужно построить тесты, которые вызывают следующие расходы: -1.00, 0.00, 100000.00 и 100000.25.
4) Использовать правило 2) для каждого выходного условия. Например, если система информационного поиска отображает на экране терминала не более 8наиболее подходящих рефератов для входного запроса, то следует составить тесты, которые могли бы вызвать выполнение программы с отображением 0, 1, 8, >8 рефератов.
5) Если вход или выход программы – упорядоченное множество (например, линейный список, таблица, последовательный файл), то следует разработать тесты для обработки первого и последнего элементов этого множества.
Одним изнедостаткованализа граничных значений и эквивалентногоразбиения является то, что они не исследуют комбинации входных условий. Например, если тестируется некоторая программа социологического опроса, то она может не обнаружить ошибку, связанную с превышением произведения числа вопросов и числа респондентов, хотя такая ошибка не обязательно будет обнаружена тестированием граничных значений.
Тестирование комбинаций входных условий – сложная задача, поскольку даже при эквивалентном разбиении входных условий число комбинаций классов эквивалентности может быть очень большим. Если нет систематического способа выбора подмножества входных условий, то, как правило, выбирается произвольное подмножество, приводящее к неэффективному тесту.
§
Метод функциональных диаграмм или диаграмм причинно-следственных связей помогаетсистематически выбирать высокорезультативные тесты. Кроме этого, метод функциональных диаграмм дает полезный побочный эффект, так как позволяет обнаруживать неполноту и неоднозначность исходных спецификаций.
Функциональная диаграмма – это формальный язык, на который транслируется спецификация, написанная на естественном языке.
Методика использования функциональных жиаграмм:
1. Спецификация разбивается на “рабочие” участки, так как для больших спецификаций функциональные диаграммы становятся слишком громоздкими. Например, при тестировании компилятора в качестве рабочего участка можно рассматривать каждый отдельный оператор языка программирования.
2. В спецификации определяются причины и следствия. Причина – это отдельное входное условие или класс эквивалентных входных условий. Следствие – это выходное условие (результат выполнения программы). Например, если при выполнении программы обновляется содержимое некоторого файла, то изменение в нем является результатом выполнения программы, а подтверждающее сообщение – выходным условием.
Причины и следствия определяютсяпутем последовательного чтения спецификации. Каждым причине и следствию приписывается уникальный номер.
3. Анализируется семантическое содержание спецификации, которая преобразуется в булевский граф (функциональную диаграмму), связывающий причины и следствия.
4. Диаграмма дополняетсяпримечаниями, задающими ограничения и описывающими комбинации причин и (или) следствий, которые являются невозможными из-за синтаксических или внешних ограничений.
5. Путем методического прослеживания состояний условий диаграммы она преобразуется в таблицу решений с ограниченными входами. Каждый столбец таблицы решений соответствует тесту.
6. Столбцы таблицы решений преобразуются в тесты.
Процедура генерации таблицы решений заключается в следующем:
a) Выбрать некоторое следствие, которое должно быть в состоянии 1.
b) Найти все комбинации причин (с учетом ограничени), которые установят это следствие в 1, прокладывая из этого следствия обратную трассу через диаграмму.
c) Построить столбец в таблице решений для каждой комбинации причин.
d) Для каждой комбинации причин определить состояния всех других следствий и поместить их в соответствующий столбец таблицы решений.
При выполнении этого шага необходимо руководствоваться следующими положениями:
· Если обратная трасса прокладывается через узел ИЛИ, выход которого должен принимать значение 1, то одновременно не следует устанавливать в 1 более одного входа в этот узел. Цель данного правила – избежать пропуска определенных ошибок из-за того, что одна причина маскируется другой.
· Если обратная трасса прокладывается через узел ИЛИ, выход которого должен принимать значение 0, то все комбинации входов, приводящие выход в 0, должны быть в конечном счете перечислены. Однако, когда исследуется ситуация, где один вход есть 0, а один или более других входов есть 1, не обязательно перечислять все условия, при которых остальные входы могут быть 1.
· Если обратная трасса прокладывается через узел И, выход которого должен принимать значение 0, то необходимо указать лишь одно условие, согласно которому все входы являются нулями.
Каждый узел диаграммы может находиться в двух состояниях – 0 или 1; 0обозначает состояние “отсутствует”, а 1 – “присутствует”.
Для представления функциональных диаграмм используются следующие базовые символы:
 Если значение aесть 1, то и значение bесть 1; в противном случае значениеbесть0.
Если значение aесть 1, то и значение bесть 1; в противном случае значениеbесть0.

 Если значение aесть 0, то значение bесть 1; в противном случае значениеbесть0.
Если значение aесть 0, то значение bесть 1; в противном случае значениеbесть0.

 ФункцияИЛИустанавливает, что если a, или b,
ФункцияИЛИустанавливает, что если a, или b,
или сесть 1, тоdесть 1; в противном случае dесть 0.
 Функция И устанавливает, что если и a, и b есть 1, то и с есть 1; в противном случае сесть 0.
Функция И устанавливает, что если и a, и b есть 1, то и с есть 1; в противном случае сесть 0.
Пример
 Рассмотрим диаграмму, отображающую спецификацию: Файл обновляется, если символ в колонке 1 является буквой “A” или “B”, а символ в колонке 2 – цифра. Если первый символ ошибочный, то выдается сообщение X1, а если второй символ не является цифрой – сообщение X2.
Рассмотрим диаграмму, отображающую спецификацию: Файл обновляется, если символ в колонке 1 является буквой “A” или “B”, а символ в колонке 2 – цифра. Если первый символ ошибочный, то выдается сообщение X1, а если второй символ не является цифрой – сообщение X2.
Причины:
1 – символ “A” в колонке 1
2 – символ “B” в колонке 1
3 – цифра в колонке 2
Следствия:
7 – файл обновляется
6 – выдается сообщение X1
8 – выдается сообщение X2
Приведенная функциональная диаграмма содержит невозможную комбинацию причин: причины 1 и 2 не могут быть установлены в 1 одновременно.
Для изображения невозможных комбинаций причин используются следующие логические ограничения:

Ограничение Е устанавливает, что Е должно быть истинным, если хотя бы одна из причин – а или b – принимает значение 1 (a и b не могут принимать значение 1 одновременно).
 Ограничение I устанавливает, что по крайней мере одна из величин a, b или c всегда должна быть равной 1 (a,b и с не могут принимать значение 0 одновременно).
Ограничение I устанавливает, что по крайней мере одна из величин a, b или c всегда должна быть равной 1 (a,b и с не могут принимать значение 0 одновременно).
 Ограничение О устанавливает, что одна и только одна из величин а или bдолжна быть равна 1.
Ограничение О устанавливает, что одна и только одна из величин а или bдолжна быть равна 1.

Ограничение R устанавливает, что если a принимает значение 1, то и b должна принимать значение 1, т.е. невозможно, чтобы a было равно 1, а b – 0.
Ограничение М устанавливает, что если следствие aимеет значение 1, то следствие b должно принять значение 0.
Для рассмотренного выше примера физически невозможно, чтобы причины 1 и 2 присутствовали одновременно, но возможно, чтобы присутствовала одна из них. Следовательно, они связаны ограничением Е.
Преобразуем полученную функциональную диаграмму в таблицу решений.
Выберем следствие 7 (файл обновляется). Следствие 7имеет место, еслиузлы3 и 11есть1. В свою очередь узел 11 есть 1, если одна из причин 1 или 2 имеет значений 1. Таким образом, возможны следующие состояния узлов 1 – 3:
1 0 1 и 0 1 0.
Следствие 6 имеет место, если значение узла 11 есть 0 (узлы1 и 2оба равны 0).
Следствие 8 имеет место, если значение узла 3 есть 0.
 Таблица решений будет иметь следующий вид:
Таблица решений будет иметь следующий вид:
Столбец 1 представляет условие, где следствие 6 есть 1, столбцы 2,3 – следствие 7 есть 1, а столбец 4 соответствует условию, для которого следствие 8 есть 1.
Пробелы в таблице решений представляют “безразличные” ситуации (состояние причины несущественно).
Преобразуем таблицу решений в набор тестов:
Кол.1 Кол.2
1. 1 1
2. A 2
3. B 2
4. A A
§
Надежность программного обеспечения отличается от надежности технических средств следующим:
· элементы ПО не стареют от износа;
· число способов контроля ПО значительно больше числа способов контроля аппаратуры;
· в ПО значительно больше объектов для контроля, чем в аппаратуре;
· в ПО гораздо проще вносить исправления и дополнения, чем в аппаратуру, но это трудно делать корректно и безошибочно.
Основные понятия, связанные с надежностью программного обеспечения:
· ошибки в программах и признаки их наличия;
· количество оставшихся в программе ошибок (ошибок, дошедших до пользователя); вероятность безотказной работы программы;
· интенсивность обнаружения ошибок (или функция риска);
· прогон программы;
· отказ программы.
Дать строгое определение программной ошибки непросто, поскольку это определение является функцией от самой программы, то есть зависит от того, какого функционирования ожидает от программы пользователь. По этой причине вместо строгого определения будут перечислены только признаки, указывающие на наличие ошибки в программе:
· при выполнении программы появилась ошибочная операция;
· использование некорректного операнда в программе;
· несоответствие функций, выполняемых программой, ее спецификации;
· ошибки в самой спецификации, которые вызывают необходимость корректирования программы;
· ошибки в вычислениях (например, переполнение и т.п.);
· ошибки интерфейса программы с пользователем.
Этот список можно считать открытым, поскольку он может быть продолжен разработчиками по мере накопления ими опыта в повышении надежности программного обеспечения.
Все же чаще всего под ошибкой (или отказом) программы понимают всякое невыполнение программой функций, которые были предусмотрены в техническом задании на ее разработку или вытекают непосредственно из инструкций пользователю. Является некорректным относить к ошибкам, например, необходимость написания программного кода, заменяющего какую-либо временно отсутствующую часть программы, или же необходимость рекомпиляции, вызванную изменениями в других модулях.
Количество оставшихся в программе ошибок – это количество ошибок, которые потенциально могут быть обнаружены на последующих стадиях жизненного цикла программы, после исправлений, внесенных в программу на текущей стадии ее жизненного цикла. Это количество оставшихся в программе ошибок (обозначаемое далее как B) – один из важнейших показателей надежности ПО.
Пусть P(t) — вероятность того, что ни одной ошибки не будет обнаружено на временном интервале [0,t]. Тогда вероятность хотя бы одного отказа за этот период будет Q(t) = 1 – P(t), и плотность вероятности можно записать как
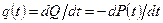
Рассмотрим функцию риска R(t), как условную плотность вероятности отказа программы в момент времени t, при условии, что до этого момента отказов не было
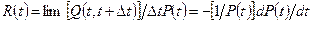 (13.1)
(13.1)
Функция риска имеет размерность [1/время] и она очень полезна при классификации основных распределений отказов. Распределения с возрастающей функцией риска соответствуют тем ситуациям, когда статистические характеристики надежности ухудшаются со временем. И наоборот, распределения с убывающей функцией риска соответствуют обратной ситуации, когда надежность улучшается со временем в результате процесса обнаружения и коррекции ошибок.
Из выражения (13.1), ясно, что 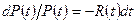 , и, следовательно,
, и, следовательно,
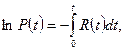
или
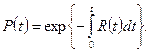 (13.2)
(13.2)
Равенство (13.2) является одним из самых важных в теории надежности. В дальнейшем будет показано, что различные виды поведения функции риска во времени порождают различные возможности для построения моделей надежности ПО. Интенсивность обнаружения ошибок (функция риска), вместе с вероятностью безотказной работы программы и количеством оставшихся в программе ошибок, являются важнейшими показателями надежности программ.
Прогон программы – это набор действий, включающий в себя: ввод в программу одной из возможных комбинаций Ei пространства входных данных E (  ); выполнение программы, которое заканчивается либо получением результата F(Ei), либо отказом.
); выполнение программы, которое заканчивается либо получением результата F(Ei), либо отказом.
Для некоторых наборов входных данных Ei, отклонение полученного на выходе результата (F’(Ei)) от требуемого результата F(Ei) находится в пределах допустимого отклонения 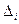 , то есть выполняется следующее неравенство
, то есть выполняется следующее неравенство
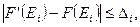 (
( 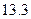 )
)
а для всех остальных Ei из подмножества 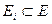 , выполнение программы не дает приемлемого результата, то есть
, выполнение программы не дает приемлемого результата, то есть
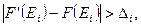 (
( 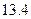 )
)
Случаи, описанные неравенством (13.4), называются отказами программы.
Рассмотрим дихотомическую переменную  :
:
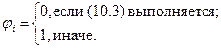
Тогда статистическая оценка вероятности отказа программы в течении m прогонов будет равна:
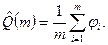 (
( 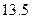 )
)
Обозначим через 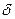 приемлемую ошибку оценки
приемлемую ошибку оценки 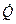 вероятности отказа
вероятности отказа 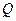 . Тогда требуемое количество прогонов программы m должно быть пропорционально значению
. Тогда требуемое количество прогонов программы m должно быть пропорционально значению 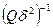 , где Q – заданная вероятность отказа программы. Это означает, что если, например, требуемая относительная ошибка оценки (13.5)
, где Q – заданная вероятность отказа программы. Это означает, что если, например, требуемая относительная ошибка оценки (13.5) 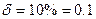 , и требуемое (желаемое) значение
, и требуемое (желаемое) значение 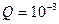 , тогда количество независимых прогонов программы m одлжно быть не меньше, чем
, тогда количество независимых прогонов программы m одлжно быть не меньше, чем 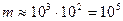 , что, конечно, нелегко реализовать на практике. Решением этой проблемы может быть использование процедуры последовательного анализа Вальда.
, что, конечно, нелегко реализовать на практике. Решением этой проблемы может быть использование процедуры последовательного анализа Вальда.
И наконец, еще один показатель надежности ПО, который тоже будет использоваться в этой работе – среднее время наработки программы до отказа:
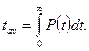
Опыт разработки ПО показывает, что выявление ошибок и их исправление связано с определенными затратами, которые составляют цену ошибки. По мере перехода к более поздним стадиям разработки цена ошибки возрастает:
1. Этап разработки спецификаций 140$;
2. Программирование 1100$;
3. Комплексная отладка 7000$;
4. Этап сопровождения от 14000$ до 140 000$;
§
Это одна из первых и простейших моделей классического типа, послужившая основой для дальнейших разработок в этом направлении. Модель была использована при разработке таких значительных программных проектов, как программа Аполло (некоторых ее модулей). Модель Джелинского-Моранды основана на следующих предположениях:
1. Интенсивность обнаружения ошибок R(t) пропорциональна текущему количеству ошибок в программе, то есть изначальному количеству ошибок за вычетом количества ошибок, уже обнаруженных на данный момент.
2. Все ошибки в программе равновероятны и не зависят друг от друга.
3. Все ошибки имеют одинаковую степень важности.
4. Время до следующего отказа программы распределено экспоненциально.
5. Исправление ошибок происходит без внесения в программу новых ошибок.
6. R(t) = const в промежутке между любыми двумя соседними моментами обнаружения ошибок.
Согласно этим предположениям, функция риска будет представлена как:
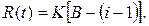
В этой формуле t – это произвольный момент времени между обнаружением (i-1)-й и i-й ошибок; K – неизвестный коэффициент масштабирования; B – начальное количество оставшихся в программе ошибок (также неизвестное). Таким образом, если в течении времени t было обнаружено (i-1) ошибок, это означает, что в программе еще остается B-(i-1) необнаруженных ошибок. Полагая, что
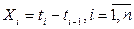
и используя предпосылку 6, а также равенство (13.2), можно заключить, что все Xi имеют экспоненциальное распределение
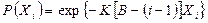

и плотность вероятности отказа, соответственно, равна
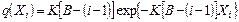
Тогда функцию правдоподобия (согласно предпосылке 2) можно записать как
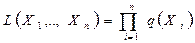
или, переходя к логарифму функции правдоподобия, имеем
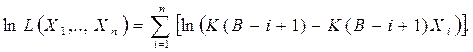 (13.2)
(13.2)
Максимум функции правдоподобия можно найти, используя следующие условия
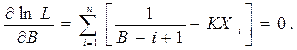 (13.3)
(13.3)
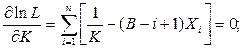 (13.4)
(13.4)
Из формулы (13.3) получается оценка максимального правдоподобия для K
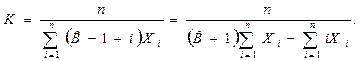 (13.5)
(13.5)
Подставляя выражение (13.5) в (13.4), находим нелинейное уравнение для вычисления 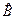 –оценки максимального правдоподобия для B
–оценки максимального правдоподобия для B
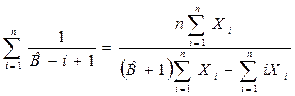 (13.6)
(13.6)
Это уравнение можно упростить перед тем, как искать его решение, если записать его с использованием следующих обозначений
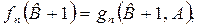 (13.7)
(13.7)
где 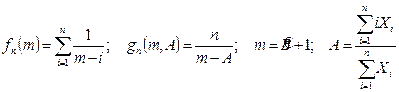
Поскольку имеют смысл лишь целочисленные значения , функции из выражения (13.7) можно рассматривать только для целочисленных аргументов. Более того, 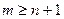 , поскольку n ошибок с программе уже обнаружено. Таким образом, оценка максимального правдоподобия для B может быть получена с помощью вычисления начальных значений функций fn(m) и gn(m) для m=n 1, n 2…, и анализа разницы |fn(m)-gn(m)|.
, поскольку n ошибок с программе уже обнаружено. Таким образом, оценка максимального правдоподобия для B может быть получена с помощью вычисления начальных значений функций fn(m) и gn(m) для m=n 1, n 2…, и анализа разницы |fn(m)-gn(m)|.
Поскольку правая и левая части выражения (13.7) одинаково монотонны, это порождает проблему единственности решения, а также проблему его существования. Конечное решение в области 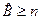 существует тогда и только тогда, когда выполняется неравенство
существует тогда и только тогда, когда выполняется неравенство
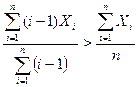 (13.8)
(13.8)
В противном случае оценка максимального правдоподобия будет 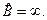 Условие (13.8) можно переписать в более удобном виде
Условие (13.8) можно переписать в более удобном виде
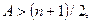 (13.9)
(13.9)
где A – то же самое выражение, что и в формуле (13.7). Необходимо отметить, что, A является интегральной характеристикой n встретившихся в программе за время тестирования ошибок, и представляет (в статистическом смысле) набор интервалов Xi между ошибками.
Рассмотрим пример использования модели Джелинского-Моранды, в котором она применяется к следующим экспериментальным данным: в течение 250 дней было обнаружено 26 ошибок, интервалы между обнаружением которых представлены в таблице 13.1. Для этих данных мы имеем n=26 и 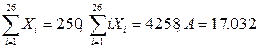 . Условие (13.9) выполняется, и, таким образом, оценка максимального правдоподобия имеет единственное решение. В таблице 13.2 представлены начальные значения функций, входящих в уравнение (13.7), для множества аргументов
. Условие (13.9) выполняется, и, таким образом, оценка максимального правдоподобия имеет единственное решение. В таблице 13.2 представлены начальные значения функций, входящих в уравнение (13.7), для множества аргументов 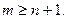
Наилучшим решением для уравнения (13.7) является m=32 (соответствующая строка в таблице дает минимальное значение разницы функций по модулю, то есть максимально приближает ее к нулю, что нам и требуется), то есть = m-1=31. Из выражения (13.5) находим  = 0.007.
= 0.007.
Среднее время 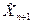 (время, оставшееся до обнаружения (n 1)-й ошибки) есть инвертированная оценка интенсивности для предыдущей ошибки:
(время, оставшееся до обнаружения (n 1)-й ошибки) есть инвертированная оценка интенсивности для предыдущей ошибки:

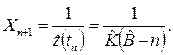
В этом примере, 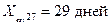 , и время до полного завершения тестирования
, и время до полного завершения тестирования 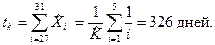
Таблица 10. Интервалы между обнаружением ошибок.
Таблица 11. Значения функций.
Простая экспоненциальная модель.
Основное различие между этой моделью и моделью Джелинского-Моранды, рассмотренной в предыдущем разделе, в том, что эта модель не использует предположение 6, и, таким образом, допускает, что функция риска может меняться между моментами обнаружения ошибок, то есть она больше не является константой на этих интервалах. Пусть N(t) – число ошибок, обнаруженных к моменту времени, и пусть функция риска пропорциональна количеству ошибок, оставшихся в программе после момента t.
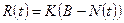
Продифференцируем обе части этого уравнения по времени:
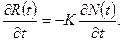
Учитывая, что 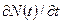 — это R(t) (количество ошибок, обнаруживаемых в единицу времени), получаем дифференциальное уравнение для R(t)
— это R(t) (количество ошибок, обнаруживаемых в единицу времени), получаем дифференциальное уравнение для R(t)
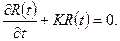 (13.10)
(13.10)
Если рассмотреть начальные значения N(0)=0, R(0)=KB, то решением уравнения (3.10) будет
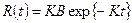 (13.11)
(13.11)
Оценки параметров К и В можно получить аналогично модели Джелинского-Моранды и затем с помощью оценки функции риска можно спрогнозировать ситуацию на следующие этапы отладки.
§
Эта модель основана на предположении, что функция риска пропорциональна не только количеству ошибок в программе, но и продолжительности процесса тестирования. Кроме того, предполагается, что чем дольше ПО тестируется, тем больше появляется шансов на обнаружение последующих ошибок, поскольку в процессе отладки некоторые участки программы «подчищаются», что облегчает ее дальнейшее тестирование.
Модель основана на следующих предположениях:
- Все ошибки в программе равновероятны и независимы друг от друга.
- Все ошибки считаются одинаково серьезными.
- Исправление ошибок происходит без внесения в программу новых ошибок.
Функция риска для данной модели:
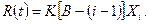
В этой формуле Xi — время между моментом  обнаружения (i-1)-й ошибки до текущего момента
обнаружения (i-1)-й ошибки до текущего момента  .
.
Вероятность безотказного функционирования программы на интервале Xi равна:
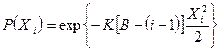 ,
,
что дает плотность вероятности отказа
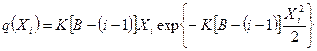
Модели Липова
Эти модели являются обобщением моделей Джелинского-Моранды и Шика-Уолвертона. В отличие от этих моделей, модели Липова допускают более одной ошибки в интервале тестирования, и кроме того, допускают, что не все из ошибок, обнаруженных а этом интервале, могут быть исправлены. Первая модель Липова (обобщение модели Джелинского-Моранды) основана на следующих предположениях:
1. Все ошибки равновероятны и независимы друг от друга.
2. Все ошибки считаются одинаково серьезными.
3. Интенсивность обнаружения ошибок постоянна на всем интервале тестирования.
4. На i-том интервале тестирования обнаруживается  ошибок, но только
ошибок, но только  из них исправляется.
из них исправляется.
Последнее предположение значительно отличает данную модель от всех моделей, рассмотренных ранее. Таким образом, функция риска определяется следующим выражением: 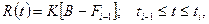 где
где 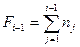 — общее количество ошибок, исправленных к моменту времени , а — это время окончания i-го интервала тестирования (измеренное обычным способом или таймером процессора). Еще одно отличие данной модели от модели Джелинского-Моранды в том, что интервалы фиксированные, а не произвольные.
— общее количество ошибок, исправленных к моменту времени , а — это время окончания i-го интервала тестирования (измеренное обычным способом или таймером процессора). Еще одно отличие данной модели от модели Джелинского-Моранды в том, что интервалы фиксированные, а не произвольные.
Вторая модель Липова (обобщение модели Шика-Уолвертона) основана на следующих предположениях. Интенсивность обнаружения ошибок пропорциональна текущему количеству ошибок в ПО и общему времени, затраченному на его тестирование, включая также «среднее» время поиска ошибки, обнаруженной на интервале тестирования. С учетом этих предположений, функция риска задается следующим выражением:
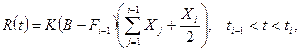 (13.12)
(13.12)
где 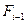 — общее количество ошибок, исправленных к моменту времени
— общее количество ошибок, исправленных к моменту времени 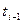 . Формула (13.12) отличается от первой модели Липова вторым множителем —
. Формула (13.12) отличается от первой модели Липова вторым множителем — 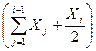 , отражающем изменение интервала тестирования.
, отражающем изменение интервала тестирования.
Геометрические модели
В этом разделе рассмотрен пример геометрической модели, предложенной П. Б. Морандой и являющейся модификацией модели Джелинского-Моранды.
Модель основана на предположении, что начальное количество ошибок в программе B не является фиксированным значением (не ограничено), более того, не все ошибки встречаются с одинаковой вероятностью. Также предполагается, что чем дольше длится процесс отладки ПО, тем труднее становится обнаруживать в нем ошибки, и , таким образом, ПО никогда полностью не освобождается от ошибок. Основные предположения в этой модели следующие:
1. Общее количество ошибок в программе неограниченно;
2. Ошибки встречаются с разной вероятностью;
3. Процесс обнаружения ошибок не зависит от самих ошибок;
4. Интенсивность обнаружения ошибок изменяется по закону геометрической прогрессии, но между моментами обнаружения ошибок интенсивность постоянна.
Исходя из этих предположений, функцию риска можно записать следующим выражением:
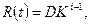
где t – временной интервал между обнаружением (i-1)-ой и i-той ошибок. Начальное значение этой функции R(0) = D, и функция риска убывает со скоростью геометрической прогрессии (0<K<1) по ходу процесса обнаружения ошибок. Скорость изменения R(t) пропорциональна инвертированному значению константы K:
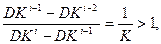
что приводит к убыванию шага изменения R(t) в процессе обнаружения ошибок. Таким образом, более поздние ошибки труднее обнаружить, и они оказывают меньшее влияние на уменьшение потока ошибок, чем предыдущие ошибки. Если снова положить 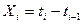 (временной интервал между обнаружением (i-1)-ой и i-той ошибок), тогда, согласно второму и третьему предположению, Xi распределены экспоненциально с плотностью распределения
(временной интервал между обнаружением (i-1)-ой и i-той ошибок), тогда, согласно второму и третьему предположению, Xi распределены экспоненциально с плотностью распределения
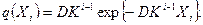
Эта модель не позволяет определить, сколько ошибок осталось в ПО, но с ее помощью можно найти его «уровень чистоты». “Уровень чистоты” — это отношение
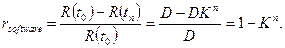 (13.13)
(13.13)
Оценка максимального правдоподобия для этого значения будет 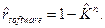
Модель Шнейдевинда
Эта модель основана на подходе, что чем позже встречаются ошибки, тем большее значение они имеют для процесса предсказания ошибок в программе. Предположим, что есть m интервалов тестирования, и пускай на i-том интервале обнаружено ошибок. Тогда возможно три различных подхода:
1. Использовать данные об ошибках на всех интервалах;
2. Не рассматривать данные об ошибках, обнаруженных на первых (s-1) интервалах, и использовать только данные с s-того по m-тый;
3. Использовать суммарное количество ошибок, обнаруженных с первого по (s-1)-ый интервал, т.е. 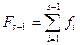 , и отдельные ошибки с s-того по m-тый интервалы.
, и отдельные ошибки с s-того по m-тый интервалы.
Подход 1 предлагается использовать в тех случаях, когда для предсказания будущего состояния ПО необходимы данные со всех интервалов тестирования. Подход 2 – когда есть причины полагать, что произошел некий перелом в процессе обнаружения ошибок, и только данные последних m – (s-1) интервалов имеет смысл учитывать в прогнозах на будущее. И наконец, подход 3 является компромиссом между первыми двумя подходами.
Модель основана на следующих предположениях:
1. Количество ошибок на интервале тестирования не зависит от количества ошибок на остальных интервалах;
2. Количество обнаруженных ошибок убывает от одного интервала к другому;
3. Все интервалы тестирования имеют одинаковую длину;
4. Интенсивность обнаружения ошибок пропорциональна количеству ошибок, содержащихся в программе в текущий момент времени.
Лекция 14. Модели, основанные на методе «посева» и разметки ошибок, и модели на основе учета структуры входных данных
Методы оценки надежности программ, основанные на моделях «посева» и разметки ошибок, рассмотрены на примере трех моделей: Милза, Бейзина и простой эвристической модели. Согласно методике, предложенной Милзом, программа изначально “засевается” известным количеством некоторых ошибок — M. Главное предположение модели в том, что «засеянные» ошибки распределены таким же образом, как и естественные ошибки программы, и, следовательно, вероятность обнаружения для «засеянной» ошибки такая же, как и для естественной. После этого начинается процесс тестирования ПО. Пусть во время тестирования было обнаружено (m v) ошибок, из которых m ошибок было искусственно «засеяно», а v ошибок содержалось в ПО изначально. Тогда, согласно методу максимального правдоподобия, начальное количество ошибок в программе можно оценить следующим образом: 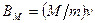 .
.
Серьезным недостатком этой модели является предположение об одинаковости распределения сгенерированных и естественных ошибок, которое невозможно проверить, особенно на более поздних стадиях разработки ПО, когда многие простые ошибки (такие, как синтаксические ошибки, например) уже исправлены, и только наиболее сложные для обнаружения ошибки еще остаются в ПО.
Теперь рассмотрим модель Бейзина. Пусть программный продукт содержит Nk команд. Из этих Nk команд произвольно выбираются n команд, и в каждую из этих n команд заносится ошибка. После этого для тестирования случайным образом выбирается r команд. Если в процессе тестирования было случайным образом обнаружено m “засеянных” и v естественных ошибок, это означает, что, согласно методу максимального правдоподобия, начальное количество ошибок в программе можно оценить следующим образом:
 где скобками ][ обозначена целая часть числа.
где скобками ][ обозначена целая часть числа.
При использовании такой процедуры уровень пометки (т.е. среднее количество помеченных команд) должен превышать 20, чтобы полученную оценку можно было считать достаточно объективной. Эти процедуры могут применяться на любой стадии после того, как написание кода программы закончено.
Теперь рассмотрим простую эвристическую модель. Эта модель была предложена Б. Руднером. Она позволяет избавиться от главного недостатка модели Милза. Здесь тестирование производится параллельно, двумя независимыми группами разработчиков ПО.
Пусть  и
и 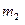 — количество ошибок, обнаруженных, соответственно, первой и второй группами, а
— количество ошибок, обнаруженных, соответственно, первой и второй группами, а 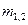 — количество общих ошибок, то есть обнаруженных обеими группами, первой и второй. Начальное количество ошибок, содержащихся в программе, можно оценить, используя гипергеометрическое распределение и метод максимального правдоподобия
— количество общих ошибок, то есть обнаруженных обеими группами, первой и второй. Начальное количество ошибок, содержащихся в программе, можно оценить, используя гипергеометрическое распределение и метод максимального правдоподобия
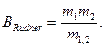
§
Модель, предложенная Е. Нельсоном, основана на использовании структуры входных данных программы. В простейшем случае набор входных данных Ei, произвольно выбранный из пространства входных данных E, имеет равную априорную вероятность с другими наборами, входящими в E, и это дает оценку вероятности отказа по формуле (13.5).
Если рассмотреть также и случай различных вероятностей 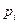 для каждого набора данных, то оценка (13.5) изменится следующим образом.
для каждого набора данных, то оценка (13.5) изменится следующим образом.
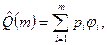
что позволяет записать следующее выражение для вероятности успешного прогона:
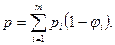 (14.1)
(14.1)
Тогда вероятность успешного выполнения m прогонов, при условии, что набор входных данных для каждого прогона выбирается независимо и в соответствии с распределением, заданным формулой (14.1), будет равна:
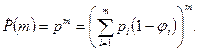 (14.2)
(14.2)
Модель (14.2) позволяет дать следующее определение надежности ПО: надежность ПО – это вероятность его m безотказных прогонов.
Следующим шагом в развитии этой модели будет признать, что, как правило, предположение о том, что выбор входных данных происходит независимо для каждого прогона, на практике неверно. Исключение могут составлять только последовательности прогонов с постепенным увеличением значения входной переменной, или с использованием определенной последовательности процедур (как в системах реального времени).
Принимая во внимание эти обстоятельства, необходимо переопределить распределение (14.1) в терминах вероятностей pij выбора набора данных Ei для j-того прогона программы из некоторой последовательности прогонов. Тогда вероятность отказа на j-том прогоне будет
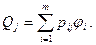
Соответственно, вероятность безотказного выполнения m прогонов можно оценить следующим выражением:
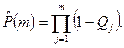
Это выражение можно записать в виде 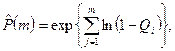
и если Qi<<1, тогда 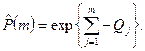
Обозначим 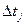 — время выполнения j-того прогона программы, и
— время выполнения j-того прогона программы, и 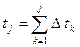 — суммарное время, потраченное на выполнение j прогонов, и будем использовать следующее выражение для функции риска
— суммарное время, потраченное на выполнение j прогонов, и будем использовать следующее выражение для функции риска
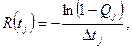
тогда мы имеем
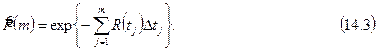
Если 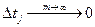 , то сумма превращается в интеграл, и формула (14.3) превращается в фундаментальное отношение (13.2):
, то сумма превращается в интеграл, и формула (14.3) превращается в фундаментальное отношение (13.2):
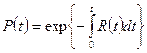
основного правила надежности.
При использовании модели Нельсона на практике встречаются две категории трудностей. Первая связана с нахождением 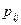 — параметров распределения входных данных. Вторая связана с необходимостью выполнения значительного количества прогонов программы (десятки и сотни тысяч) для получения приемлемой точности для соответствующих оценок вероятности (отказа или безотказной работы). Последняя проблема решается применением хорошо известного в статистике метода последовательного анализа, предложенного Вальдом.
— параметров распределения входных данных. Вторая связана с необходимостью выполнения значительного количества прогонов программы (десятки и сотни тысяч) для получения приемлемой точности для соответствующих оценок вероятности (отказа или безотказной работы). Последняя проблема решается применением хорошо известного в статистике метода последовательного анализа, предложенного Вальдом.
Модель, разработанная специалистами компании IBM.
Во время эксплуатации пользователем текущей версии ПО разработчики, как правило, занимаются активным сопровождением этого программного продукта, то есть вносят некоторые улучшения или исправления в данную версию, не дожидаясь, пока пользователь этого потребует. И это сопровождение может включать в себя также добавление новых функций в ПО. С некоторого момента, когда разработчик считает свою задачу выполненной, начинается, так называемое, пассивное сопровождение, когда исправления вносятся уже только по запросу пользователя.
В течение сопровождения в ПО вносится значительное количество новых ошибок в каждой новой версии, вместе с доработками, изменениями и исправлениями, что требует исправлений также и в следующей версии. Разработчики известной компании IBM попытались предсказать количество подобных исправлений от версии к версии, основываясь на большом количестве экспериментальных данных, собранных в ходе сопровождения операционной системы OS/360. Модель, предложенная специалистами IBM, основана на наблюдении за ходом разработки этого программного продукта, и на гипотезе о статистической стабильности зависимости между параметрами, характеризующими различные версии системы. В качестве основной единицы измерения сложности ПО был выбран программный модуль. Были стандартизованы правила создания модулей.
Объем i-той версии выражается количеством модулей Mi, входящих в данную версию. При выпуске i –той версии системы изменялся параметра СИМi (количества старых исправляемых модулей), и добавление некоторого числа новых модулей НМi , так что  .
.
При доработке i-й версии (в период подготовки (i 1)-й) происходит дальнейшая коррекция модулей. Эти исправленный модули делятся на две группы: первая группа характеризуется параметром MИMi – многократно изменяемые модули (10 или более исправлений на модуль), и вторая группа – ИMi, модули с числом исправлений меньше 10. Эта классификация необходима для упрощения вычислений, а также из-за того факта, что небольшое число исправлений характерно для большинства модулей.
Также необходимо отметить, что группа ИM не требуют особых средств отладки, в то время как группа MИM может потребовать некоторых дополнительных усилий при отладке.
В ходе анализа истории сопровождения OS/360 фирмы IBM было установлено, что существует значительная зависимость между параметрами, характеризующими масштабы изменений и (соответственно) уровень содержания ошибок (в группах ИM и MCM), и параметрами, характеризующими сложность и объем следующей версии (СИМ, НМ). В применении к OS/VS1 это соотношение выглядело следующим образом.
 (14.7)
(14.7)
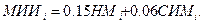 (14.8)
(14.8)
Если предположить, что термины “исправление” и “ошибка” идентичны, то тогда модель для оценивания общего количества ошибок в программе, предложенная специалистами из IBM и основанная на приведенных выше объяснениях, записывается следующим образом:
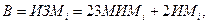 (14.9)
(14.9)
где ИЗМi — общее количество исправлений, внесенное в модули (или, другими словами, общее количество ожидаемых ошибок), а коэффициенты 23 и 2 – среднее количество исправлений на модуль для групп MИM и ИM, соответственно.
Прогноз основывается на запланированном количестве исправлений в старых модулях и на количестве добавляемых модулей (СИМi, НМi) для реализации новых требуемых функций ПО. Если количество действительно внесенных исправлений меньше, чем предсказанное количество исправлений, то можно сделать вывод, что в ПО существует еще некое количество необнаруженных ошибок. Модель фирмы IBM позволяет сделать следующие выводы:
Ø на этапе пассивного сопровождения ПО (ИMi = 0, СИМi невелико) количество исправляемых модулей и количество исправлений внутри модулей быстро убывает от версии к версии;
Ø количество ожидаемых ошибок в следующей версии может увеличится по сравнению с прошлой версией, если достаточно много старых модулей было изменено (СИМ), и/или было добавлено много новых модулей (НМ).
Ø Добавление новых модулей оказывает более сильное влияние на рост числа новых ошибок, чем исправления, вносимые в старые модули; в то же время, если есть возможность создать новый модуль вместо изменения старых модулей (5 или более), то это снижает ожидаемое количество ошибок. Другими словами, на некотором этапе сопровождения ПО изменение уже существующих модулей теряет свою эффективность, и требуется добавление вместо этого нового модуля.
§
Так как в программах нет необходимости “ремонта” компонент с участием человека, то можно добиваться высокой автоматизации программного восстановления. Главной задачей становится восстановление за время, не превышающее порогового значения между сбоем и отказом. Автоматизируя процесс и сокращая время восстановления, можно преобразовать отказы в сбои и тем самым улучшить показатели надежности функционирования системы.
Комплексы программ в процессе функционирования находятся под воздействием шумов-возмущений различных типов. Для снижения их влияния на результаты следует применять фильтры, позволяющие обнаруживать искажения, устранять или уменьшать их вредные последствия. Разнообразие видов искажений приводит к необходимости построения систем фильтров, каждый из которых способен селектировать некоторые виды искажений.
Для реализации фильтров, обеспечивающих повышение надежности функционирования программ и защиту вычислительного процесса и информации программно-алгоритмическими методами, используется программная, информационная и временнаяизбыточность. Основная задача ввода избыточности состоит в исключении возможности аварийных последствий от возмущений, соответствующих отказу системы. Любые аномалии при исполнении программ необходимо сводить до уровня сбоя путем быстрого восстановления.
Временная избыточность состоит в использовании некоторой части производительности ЭВМ для контроля исполнения программ и восстановления вычислительного процесса. Величина временной избыточности зависит от требований к надежности функционирования системы и находится в пределах от 5-10% производительности однопроцессорной ЭВМ до трех-четырех кратного дублирования производительности машины. Временная избыточность используется на обнаружение искажений, их диагностику и на реализацию операций восстановления. На это требуется в общем случае небольшой интервал времени, который выделяется либо за счет резерва, либо за счет сокращения времени решения функциональных задач.
Информационная избыточность состоит в дублировании накопленных исходных и промежуточных данных, обрабатываемых комплексом программ. Избыточность используется для сохранения достоверности данных, которые в наибольшей степени влияют на нормальное функционирование программ или требуют значительного времени восстановления. Для менее важных данных информационная избыточность используется в виде помехозащитных кодов, позволяющих только обнаружить искажение.
Программная избыточность используется для контроля и обеспечения достоверности наиболее важных решений по управлению и обработке информации. Она заключается в применении нескольких вариантов программ, различающихся методами решения задачи или программной реализацией одного и того же метода. Программная избыточность необходима также для реализации программ контроля и восстановления данных с использованием информационной избыточности и для функционирования всех средств защит, использующих временную избыточность.
§
Надежность функционирования комплексов программ зависит от многих факторов, которые можно объединить в три группы (табл.. 12).
n факторы,непосредственно определяющие возникновение отказов, и характеристики надежности программ;
n методы, способствующие проектированию корректных программ, снижающие вероятность программных ошибок и отказовых ситуаций при исполнении программ;
n метод, активно влияющие на повышение надежности функционирования программ позволяющие контролировать и поддерживать заданные показатели надежности.
Таблица 12.
| Факторы, непосредственно определяющие надежность программ | Методы проектирования корректных программ | Методы контроля и обеспечения надежности программ |
| Особенности внешних абонентов и пользователей результатов программ | Структурное проектирование программ и данных | Методы использования избыточности |
| Требования к показателям надежности | Структурное проектирование программных модулей | Временной Информационной Программной |
| Инерционность внешних абонентов | Структурное проектирование взаимодействия модулей | Методы контроля программ, данных и вычислительного процесса |
| Необходимое время отклика на входные данные | Структурирование данных | Предпусковой контроль Оперативный контроль |
| Искажения исходных данных | Тестирование программ | Методы программного восстановления |
| Искажения данных поступающих от человека | Детерминированное тестирование | Восстановление текстов программ Исправление данных |
| Искажения данных поступающих по телекодовым каналам связи | Статистическое тестирование | Корректировка вычислительного процесса |
| Искажения данных в процессе накопления и хранения в ЭВМ | Динамическое тестирование и контроль пропускной способности в реальном времени | Методы испытаний на надежность Форсированные испытания |
| Ошибки в программах и их проявление | Испытания в нормальных условиях эксплуатации | |
| Статистические характеристики ошибок и искажений: | Расчетно-экспериментальные методы определения надежности | |
| Программ | Методы обеспечения надежности при сопровождении | |
| массивов данных | Обеспечение сохранности программ эталонных версий | |
| Вычислительного процесса | Обеспечение корректности внесения изменений и развития версий |
Отказы при функционировании программ возникают вследствие взаимодействия данных и ошибок в программе. Характеристики ошибок в значительной степени определяются методами проектирования программ.Активные методы обнаружения и локализации программных ошибок базируются на тестировании различных видов: детерминированном, статистическом и динамическом. Однако все виды тестирования не гарантируют отсутствие ошибок в комплексах программ и высокую надежность. Для этого применяются методы контроля и обеспечения надежности программ путем использования программной, временной и информационной избыточности.
Ситуации проявления ошибок при исполнении программ можно разделить на три группы:
n Отказ — искажения вычислительного процесса, данных или программ, вызывающие полное прекращение выполнения функций системой;
n Искажения, кратковременно прерывающие функционирование системы — отказовые ситуации или сбои, характеризующиеся быстрым восстановлением без длительной потери работоспособности;
n Искажения, мало отражающиеся на вычислительном процессе — сбои и искажения, не создающие отказовые ситуации.
Основным показателем при классификации конкретных видов искажений является возможное время восстановления и степень проявления последствий произошедшего сбоя или отказовой ситуации:
n зацикливание, т.е. последовательная повторяющаяся реализация некоторой группы команд, не прекращающаяся без внешнего (для данного цикла) вмешательства;
n останов исполнения программ и прекращение решения функциональных задач;
n полная самоблокировка вычислительного процесса (клинч) из-за последовательного прекрестного обращения разных программ к одним и тем же ресурсам ЭВМ без освобождения ранее занятых ресурсов;
n прекращение или значительное снижение темпа решения некоторых задач вследствие перегрузки ЭВМ по пропускной способности;
n значительное искажение или полная потеря накопленной информации о текущем состоянии управляемого процесса или внешних абонентов;
n искажение процессов взаимного прерывания программ, приводящее к блокировке возможности некоторых типов прерываний.
§
Выбор метода оперативного восстановления происходит в условиях неопределенности сведений о характере отказовой ситуации и степени ее влияния на работоспособность программ.
Каждый метод восстановления характеризуется следующими статическими параметрами:
n вероятность полного восстановления нормального функционирования комплекса программ при данном методе (p3);
n затратами ресурсов ЭВМ на проведение процедуры восстановительных работ выбранным методом (b3);
n длительностью проведения работ по восстановлению — суммарным временем выбора метода восстановления и временем его реализации(t3)
Показатели восстановления p3 и t3 непосредственно влияют на показатели надежности функционирования комплекса программ. Если операции по восстановлению работоспособности комплекса программ при отказовой ситуации полностью завершаются за время меньше tд и после этого продолжается нормальное функционирование, то происшедшее искажение в работе программ не учитывается как отказ и не влияет на основные показатели надежности.
Процесс функционирования комплекса программ на однопроцессорной ЭВМ в реальном масштабе времени с учетом операций контроля и восстановления можно представить графом состояний, дуги которого соответствуют возможным переходам между состояниями за некоторый интервал времени.
Основные состояния следующие:
0- состояние соответствует нормальному функционированию работоспособного комплекса программ при полном отсутствии искажений — полезная работа;
1- состояние имеет место при переходе комплекса программ в режим контроля функционирования и обнаружения ошибок — состояние контроля;
2- состояние соответствует функционированию программ при наличии искажений, не обнаруженных средствами контроля — состояние необнаруженного искажения данных или вычислительного процесса, которое, в частности может соответствовать отказу;
3- состояние характеризуется функционированием группы программ восстановления режима полезной работы и устранения последствий искажения — восстановление после действительного искажения;
4- состояние соответствует также восстановлению режима полезной работы, но после ложного обнаружения проявления искажения, когда в действительности состояние полезной работы не нарушалось — восстановление после ложной тревоги.
Переходы между состояниями могут происходить в некоторых направлениях случайно или коррелированно с предыдущем переходом (рис. 5.3, диаграмма 1 ). Пребывание во всех состояниях, кроме нулевого, сопряжено с затратами производительности ЭВМ на выполнение операций, не связанных с прямыми функциональными задачами, и может рассматриваться как снижение общей эффективности комплекса программ и производительности ЭВМ. При определении показателей надежности учитывается только такая цепочка последовательных состояний вне работоспособности, которая оказывается протяженности больше  . Все остальные более короткие выходы из нулевого состояния не влияют на показатели надежности.
. Все остальные более короткие выходы из нулевого состояния не влияют на показатели надежности.
Методы испытаний программ на надежность.
В теории надежности разработан ряд методов, позволяющих определить характеристики надежности сложных систем. Эти методы можно свести к трем основным группам:
n прямые экспериментальные методы определения показателей надежности систем в условиях нормального функционирования;
n форсированные методы испытаний реальных систем на надежность;
n расчетно-экспериментальные методы, при использовании которых ряд исходных данных для компонент получается экспериментально, а окончательные показатели надежности систем надежности рассчитываются с использованием этих данных.
Прямые экспериментальные методы определения показателей надежности программ в нормальных условиях функционирования в ряде случаев трудно использовать из-за больших значений времени наработки на отказ (сотни и тысячи часов).
Форсированные методы испытаний надежности программ значительно отличаются от традиционных методов испытаний аппаратуры. Форсирование испытаний может выполняться путем повышения интенсивности искажений исходных данных, а также специальным увеличением загрузки комплекса программ выше нормальной.
Особым видом форсированных испытаний является проверка эффективности средств контроля и восстановления программ, данных и вычислительного процесса. Для этого имитируются запланированные экстремальные условия функционирования программ, при которых в наибольшей степени стимулируется работа испытываемого средства программного контроля или восстановления.
Расчетно-экспериментальные методы . При анализе надежности программ применение расчетно-экспериментальных методов более ограничено, чем при анализе аппаратуры. Это обусловлено неоднородностью надежностных характеристик основных компонент: программных модулей, групп программ, массивов данных и т.д. Однако в некоторых случаях расчетным путем можно оценить характеристики надежности комплексов программ. Сочетание экспериментальных и аналитических методов применяется также для определения пропускной способности комплекса программ на конкретной ЭВМ и влияние перегрузки на надежность его функционирования.
§
В этой стадии жизненного цикла программ расширяются условия их использования и характеристики исходных данных, вследствие чего могут потребоваться изменения в программах. Для сохранения и улучшения показателей надежности комплексов программ в процессе длительного сопровождения необходимо четко регламентировать передачу комплексов программ пользователям. Целесообразно накапливать необходимые изменения в программах и вводить их группами, формируя очередную версию комплекса программ с измененными характеристиками. Версии комплекса программ можно разделить на эталонные и пользовательские (или конкретного объекта).
Эталонные версии развиваются, дорабатываются и модернизируются основными разработчиками комплекса программ или специалистами, выделенными для их сопровождения. Они снабжаются откорректированной технической документацией, полностью соответствующей программам, и точным перечнем всех изменений введенных в данную версию по сравнению с предыдущей.
Пользовательские версии . Необходимы также общие проверки работоспособности и сохранности всех программ комплекса. Для корректности выполнения изменений они снабжаются методиками проверки и правилами подготовки контролирующих тестов. . Целесообразно ограничивать доступ широких пользователей к технологической документации, хранящей подробные сведения о содержании и логике функционирования программ. Такие меры в некоторой степени предотвращают возможность резкого ухудшения показателей надежности.
ЛИТЕРАТУРА
Основная
1. Липаев В.В. Качество программного обеспечения. — М.: Финансы и статистика, 1983. -263с.
2. Назаров С.В., Барсуков А.Г. Измерительные средства и оптимизация вычислительных систем. — М.: Радио и связь, 1990. -248с.
3. Боэм Б.У. Инженерное проектирование программного обеспечения: Пер. с англ. — М.: Радио и связь, 1985. -512с.
4. Авен О.И. и др. Оценка качества и оптимизация вычислительных систем. — М.: Наука, 1982. -485с.
5. Кузовлев В.И., Шкатов П.Н. Математические методы анализа производительности и надежности САПР, М.: Высшая школа, 1990.
6. Липаев В.В. Надежность программного обеспечения. — М.: Энергоиздат, 1981. -241с.
7. Липаев В.В. Проектирование программных средств. — М: Высшая школа, 1990. -301с.
8. Липаев В.В. Тестирование программ. — М.: Радио и связь, 1986. -294с.
9. Р.Калбертсон и др. Быстрое тестирование. Пер. с англ.. — М.: Изд.дом «Вильямс», 2002-384с.
Дополнительная:
10.Коган Б.И. Экспериментальные исследования программ. — М.: Наука, 1988. -184с.
11.Боэм Б. и др. Характеристики качества программного обеспечения. Пер. с англ. Е.К.Масловского. — М.: Мир, 1981. -208с.
12.Кожевникова Г.П. Структуры данных и проектирование эффективной вычислительной среды. — Львов: Вища школа, Изд. ЛГУ, 1986. -278с.
13.Холстед М.Х. Начала науки о программах. — М.: Финансы и статистика,1981.-128с.
14.Бровин Н.Н. и др. Оценка эффективности алгоритмов и программ. Ленинград.: ЛИАП 1983.-31с.
Принципы ии
Прежде чем описываться технологические принципы, без которых немыслимо развитие искусственного интеллекта, стоит познакомиться с этическими законами робототехники. Их в 1942 году вывел Айзек Азимов в своём романе «Хоровод»:
- Робот или система с искусственным интеллектом не может навредить человеку своим действием или же своим бездействием допустить, чтобы человеку был приченен вред.
- Робот должен повиноваться приказам, которые получает от человека, кроме тех, которые противоречат Первому закону.
- Робот должен заботиться о своей безопасности, если это не противоречит Первому и Второму Законам.
До выхода в свет романа Азимова, искусственный интеллект ассоциировался с образом Франкенштейна Мэри Шелли. Искусственно созданное подобие человека с разумом восстает против людей. Эту же страшилку перенесли и в знаменитый блокбастер Голливуда «Терминатор».
Интересен факт, что в 1986 году Айзек Азимов дописал еще один пункт к законам робототехники. Писатель предпочел назвать его «нулевым»:
0. Робот не может навредить человеку, если только не докажет, что в конечном итоге это (вред) будет полезно для всего человечества.
Разобравшись с этическими законами, перейдем к технологическим принципам искусственного интеллекта:
- Машинное обучение (МО) – принцип развития ИИ на основе самообучающихся алгоритмов. Участие человека при таком подходе ограничивается загрузкой в «память» машины массива информации и постановкой целей. Существует несколько методик МО: обучение с учителем – человек задает конкретную цель, хочет проверить гипотезу или подтвердить закономерность. Обучение без учителя – результат интеллектуальной обработки данных неизвестен – компьютер самостоятельно находит закономерности, учится думать как человек. Глубокое обучение – это смешанный способ, главное отличие в обработке больших массивов данных и использование нейросетей.
- Нейросеть – математическая модель, которая имитирует строение и функционирование нервных клеток живого организма. Соответственно в идеале – это самостоятельно обучаемая система. Если перенести принцип на технологическую основу, то нейросеть – это множество процессоров, которые выполняют какую-то одну задачу в масштабном проекте. Другими словами суперкомпьютер – это сеть из множества обычных компьютеров.

- Глубокое обучение относят в отдельный принцип ИИ, так как этот метод используется для обнаружения закономерностей в огромных массивах информации. Для такой непосильной человеку работы, компьютер использует усовершенствованные методики.
- Когнитивные вычисления – одно их направлений ИИ, которое изучает и внедряет процессы естественного взаимодействия человека и компьютера, наподобие взаимодействия между людьми. Цель технологии искусственного интеллекта заключается в полной имитации человеческой деятельности высшего порядка – речь, образное и аналитическое мышление.
- Компьютерное зрение – это направление ИИ используется для распознавания графических и видеоизображений. Сегодня машинный интеллект может обрабатывать и анализировать графические данные, интерпретировать информацию в соответствии с окружающей обстановкой.

- Синтезированная речь. Компьютеры уже могут понимать, анализировать и воспроизводить человеческую речь. Мы уже можем управлять программами, компьютерами и гаджетами с помощью речевых команд. Например, Siri или Google assistant, Алиса в Яндексе и другие.
Кроме того, трудно представить существование искусственного интеллекта без мощных графических процессоров, которые являются сердцем интерактивной обработки данных. Для интеграции ИИ в различные программы и устройства необходима технология API – программные интерфейсы приложений.







